16. Reformer 论文翻译笔记
16. Reformer 论文翻译笔记
机构:Google Research 、U.C. Berkeley
作者:Nikita Kitaev、Łukasz Kaiser、Anselm Levskaya
论文地址:https://arxiv.org/pdf/2001.04451.pdf
收录会议:ICLR2020
论文代码:https://github.com/google/trax/tree/master/trax/models/reformer
Reformer, 主要是对Transformer的计算复杂度和内存进行优化,最关键的两个点是:
- 局部敏感哈希
- 可逆的残差连接
摘要
大型Transformer模型常常在大量任务上取得最佳成绩,但是训练这些模型是非常昂贵的。本文引入两种计算来提升Transformer的效率。
- 第一,用局部敏感哈希代替点乘式的attention,使其空间复杂度从降低到,其中L是文本序列的长度。
- 此外,用可逆的残差连接层代理标准残差, 这使得训练过程中只需要存储移除激活值, 是层数。
最终结果表明Reformer性能与Transformer相当,同时在长序列上更具有高效内存和更快。
1. 介绍
在大型的Transformer中每层网络参数超过了0.5B,网络层数上升到64层如Al-Rfou 2018 Character-level language modeling with deeper self-attention论文中。另外,Transformer模型还增大序列长度,在单一样例中,上升到1.1万文本字符长度。这导致Transformer模型只能在大型的工业研究实验室中训练,并且其并行化训练让其甚至无法在但GPU上微调。
作者假设一个5亿参数的Transformer层,因为是float,每个参数占4byte, 那么, 转化为。
对于64K字符的激活值,如果嵌入层尺寸为1024,batch size为8,总共需要64K x 1K x 8 = 0.5B floats。又是2GB左右内存。
如果作者的内存使用仅仅是一层上述的网络的话,作者甚至能在单一GPU上轻松训练序列长度为64K的大型Transformer模型。此外,整个用来训练BERT的语料也只需要17GB存储内存。那么,为什么作者甚至无法在单一机器上微调模型呢?
因为上面只估计了一层网络的内存和输入激活层的内存消耗,并没有考虑以下Transformer中主要的内存资源占用。
- N层模型的内存占用是单层的N倍大,因为实际上在反向传播过程中需要存储每层的激活值。
- 因为中间的前馈层大小是远远大于注意力激活层的,它会占用大部分内存。
- 长度为的序列注意力计算的时间和空间复杂度都是,甚至单一长度为64K的字符序列就能耗尽GPU内存。
引入Reformer模型,用以下技术能解决这些问题:
- 可逆层,首次介绍是Gomez 2017,能只存储整个模型的一个激活值的复制,这样N倍问题消失了
- 在前馈层分开激活和分块处理,消除了因素影响,降低了内存占用。
- 基于局部敏感哈希的近似注意力计算,让计算复杂度从降为,这样就能处理长序列了
跟标准Transformer相比,训练流程影响微不足道。分开激活只在实现上有影响,其数值上还等于以前Transformer一样。使用可逆的残差连接代替标准的不更笨模型,但在作者实验的所有配置上有轻微影响。最重要的,注意力中的局部敏感哈希是最大的改变,这能影响训练变化,依赖于使用共存哈希的数目。
作者实验在人工任务上,文本任务(enwik8), 使用长为64K的序列;和图像生成任务(Imagenet-64 生成),使用长为12K的训练。结果表明Reformer结果跟Transformer差不多,尤其是文本任务,有数量级级别的更高效内存效率。
2. 局部敏感哈希注意力
Dot-product attention Transformer中叫做放缩点乘注意力。输入是维度为的queries查询值和keys键值向量,以及维度的value值向量。所有的query和keys点乘,除以,然后通过softmax函数获取values的权重。实际上,用如下公式进行矩阵计算:
多头注意力 在Transformer中,采用h次不同的线性投影queries, keys和values 来代替一个维度的keys, values和queries注意力函数,对应地学习得到线性投影的注意力。注意力被并行地用于这些queries, keys和values投影子空间,得到维度的输出。它们被拼接起来,再次投影得到最终结果values。这就是多头注意力。
高效内存注意力 为了计算注意力机制的内存使用,作者把注意力集中于公式1的计算。假设Q, K, V的大小为[batch_size, length, d_model]。
主要的问题在于项,其大小为[batch_size, length, d_model。在实验部分,作者在序列长度为64K上训练模型,在该示例中,即使batch size为1,这个64K x 64K的矩阵,32位float也要16GB内存空间。这是不明智的并阻碍了在长序列上使用Transformer。值得注意的是矩阵不需要在内存中完全实现。而是可以对每个query 分开地计算注意力,这样只要在内存中计算公式1一次,然后当需要梯度时在反向传播中再计算一次。这种计算注意的方式可能低效,但是使用内存只跟length成正比。在实验部分,作者使用高效的注意力实现来跑完整的注意力并将其作为基线。
Q, K, V来自哪?
前面描述的多头注意力,就是在keys, queries和values上操作,但是作者只给一个激活值A的tensor,其形状为[batch_size, length, d_model]——来自于将句子里的字符token嵌入到向量中。为了从A中构建Q, K, 和V, Transformer用3个不同参数的线性层将A投影成Q,K和V。(就是实现多头注意力中的3个线性层如下:)
1 |
|
对于局部敏感哈希注意力,作者希望queries和keys相同(Q和K)。这很容易实现,就是使用同样的层从A投影到Q和K,另外使用不同的投影层得到V。作者调用该模型就像共享-QK的Transformer.在第5小节实验中,作者证明共享QK不影响表现,甚至作者加上用K的长度归一化项也没有影响。
哈希注意力 对于局部敏感哈希注意力,作者开始用两个tensor,Q=K和V,其形状是[batch_size, length, d_model]。作者保持多头注意力机制完整和集中于公式1中注意力计算。正如已提到的,主要的问题在项,其大小为[batch_size, length, d_model]。但要注意的是作者实际上只对。因为softmax取决于值最大的部分,那么只要集中于K中与每个中最近的部分就可以了。(两个向量点乘最大值)。例如,如果K长度为64K,对于每个只要考虑其中一个小的子集,就是说,只需要32或者64个最近的keys.这就更高效了,但是作者如何找到其中最近的keys呢?
局部敏感哈希(LSH) 在高维空间中快速地寻找最近的点可以用局部敏感哈希LSH。如果按邻近的向量能以高概率获得相同的哈希值,远的则不能的哈希方案分配每个向量给哈希函数,这就叫局部敏感。作者实例中,实际只要邻近向量以高概率得到相同的哈希值,并且哈希桶也以高概率具有相同大小。
作者用如图1所示的随机投影方法,得到b的哈希值,作者首先固定一个随机矩阵R,大小为[],来得到b。然后定义,其中[u; v]表示拼接两个向量。该方法被称为LSH方案,其很容易实现并应用于批次的向量。

如下图所示,图来自于Inference 1.就是key用不同的随机投影会得到一个值,将这些值组合起来就是对应的哈希桶,这只要保证投影时相近的点投影后在哈希桶是一样的就可以了。

LSH注意力 了解了本文的LSH方案和通常的哈希注意力想法后,现在开始形式化本文的LSH注意力。首先,作者重写标准注意力的公式1,对于一个第i个query有:
这里,引入表示位置i处的query,z表示配分函数(就像softmax的归一化项)。为了表达清晰,忽略放缩项。
出于批次目的,作者通常在更大的集合上用注意力,同时掩码不在中的元素:
上面公式的意思是,对于不能attention的位置,为正无穷,那么是正无穷,最后还是0。
现在作者转向LSH attention,query中位置i所能够注意到的集合被限制到一个哈希桶中。
如下图2(a-b)部分是完整的attention和哈希变种attention的对比简图。(a)部分描述完整的注意力矩阵通常是稀疏的,但在计算上稀疏是没有优势的。(b)部分中,queries和keys已经按照它们的哈希桶排序了。因为相似项会以高概率掉入同样的哈希桶中,完整的attention模式可以通过只让注意力在每个桶内来近似。
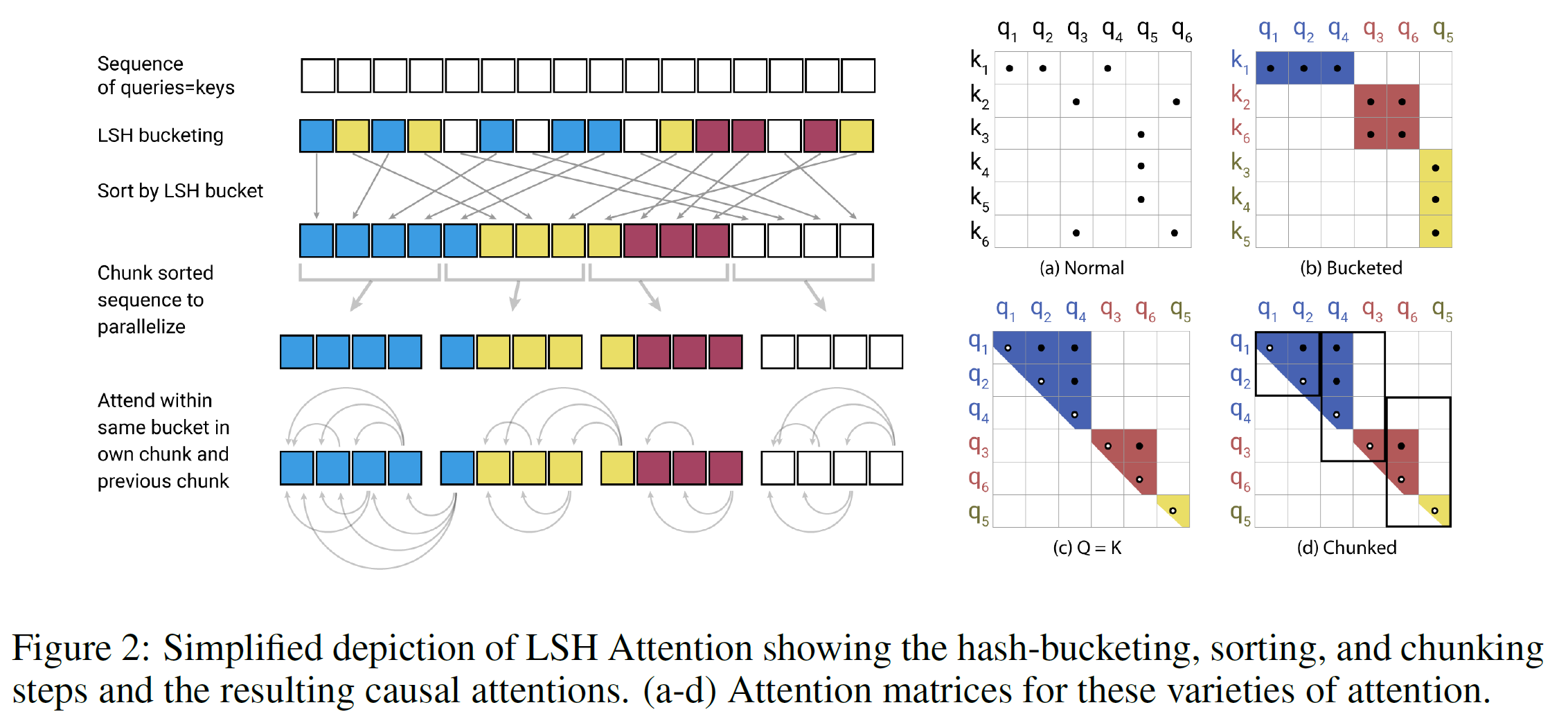
这个公式中哈希桶的大小往往不均匀,这使得跨桶批处理变得困难。并且,实际过程中桶内的queries和keys的数目也可能不一样,可能一个桶中含有大量queries但没有keys。
为了缓解这个问题,作者首先通过设置来确保。接下来,作者先按照桶号对桶排序,在每个桶内按照序列的位置排序,这得到一个新的排序后的序列。
(如图d中序列 到 ) 在这个排序的注意力矩阵中,一对来自同一桶中将聚类到对角线附近(如上图c部分).作者能遵循批量方法,将queries分词m块(排序后),每块注意到自己和前一个块(如上图d)。按照之前记号,对应着下面设置:
如果,那么.实际上,作者设置(l是queries序列长度)。平均每个桶的大小为,并且假定一个桶增长到两倍大小的概率足够低。LSH注意力整体流程如上图2所示。
总结来说,整个过程就如左半边图:
首先作者令输入序列的queries = keys
然后作者对其做LSH bucketing,得到每个query和key都在各自的bucket中(不同颜色表示)
作者跟根据bucket对query进行排序,同个bucket中,按照query原本的position进行排序。
在之后作者对于每个排序后的新序列,进行chunk 拆分
最后作者对于每个query只管制自己以及自己之前的chunk,对于这些候选集中相同bucket的key进行attend。
——Reformer详解
多轮局部敏感哈希注意力 用hash总会有很小的概率让相似的项掉落不同的桶中。这个概率可以用轮不同的哈希函数来减小如:
多轮实例本质上是并行执行LSH注意力轮;具体细节流程描述在附录A。
共享QK注意力的原因掩码 在Transformer解码器中,掩码(如公式3表示的)被用来阻止注意到未来的位置。为了实现LSH注意力,作者将每个query/key向量和一个位置索引相连,使用用于对query/key向量进行排序的相同排列再次对位置索引排序,然后用比较操作来计算掩码。
然而注意到未来是不允许的,通常Transformer实现方法是这样做,允许注意到自身。这种做法在共享-QK公式中是不行的因为query点乘自身,总是好于点乘其它的向量。因此修改掩码来禁止token注意到自身,除非token没有其它有效的注意目标(如序列中第一个token).
2.1 综合任务分析
为了验证LSH注意力的表现和研究其方法,作者开始用一个综合任务:复制一个符号序列。在该任务中,每一个训练和测试样本形如,是一个从1到N的符号序列(实验中N=127).w长度为3的示例如下:

为了研究LSH注意力,作者在样本形如0w0w,其中w长度为511上训练(整个输入0w0w长为1024). 由于这是一个语言建模任务,作者总是在给定之前所有字符条件下预测下一个字符,但是作者掩码损失和准确了却只考虑了输入后半部分的位置,即那些实际可被预测到的位置。
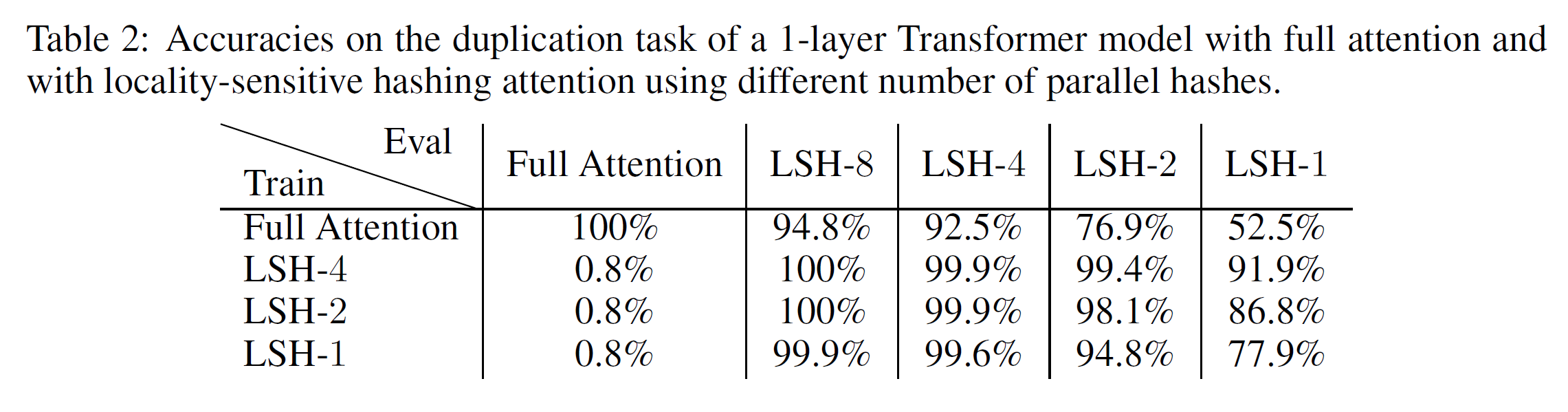
上述任务能被一层Transformer模型完美解决(准确率100%, loss=0)。但需要注意的是,它需要非局部注意力查找(non-local attention lookups),因此依赖于有限跨度的的稀疏注意力模型都无法解决该问题。为了让其变得容易和快速训练但类似于NLP中使用的模型,作者使用一层Transformer: , 4个头。用4种不同设置训练模型150K步:完整的注意力, 分别为1, 2, 4的LSH注意力。
结果总结如下表2,完整注意力模型可以立即被LSH注意力模型使用,但准确率会损失一些。当从头开始训练LSH注意力,用4轮哈希的模型几乎达到完美的准确率。有趣的是,用8轮哈希来评估就是完美的。1轮或者2轮都会下降一些。模型在越少轮哈希上训练结果越差,但即使只用1轮哈希序列,用8轮哈希来评估也几乎完美。
3. 可逆的Transformer
如上面部分所示,用一种近似的方法将注意力的复杂度从长度的平方降到线性,这是可以接受。但是如下表1清楚展示,每一栏都以项开始: 或者被替换,这种内存占用代价是不可避免的。真正地,在每层之前的激活函数已经是了, 所以内存占用上层模型至少要。甚至更差:Transformer内部的前馈层会达到。在大型的Transformer中通常设置,不切实际地,这会达到16GB内存占用。

在这部分,作者将展示如何减少这种内存占用,首先用可逆层来处理项部分,然后展示如何分块来处理问题。每个方法在内存和时间复杂度上的效果总结和下表3。

RevNets 可逆残差网络论文提出用于解决图片问题的ResNets中,如下图所示。
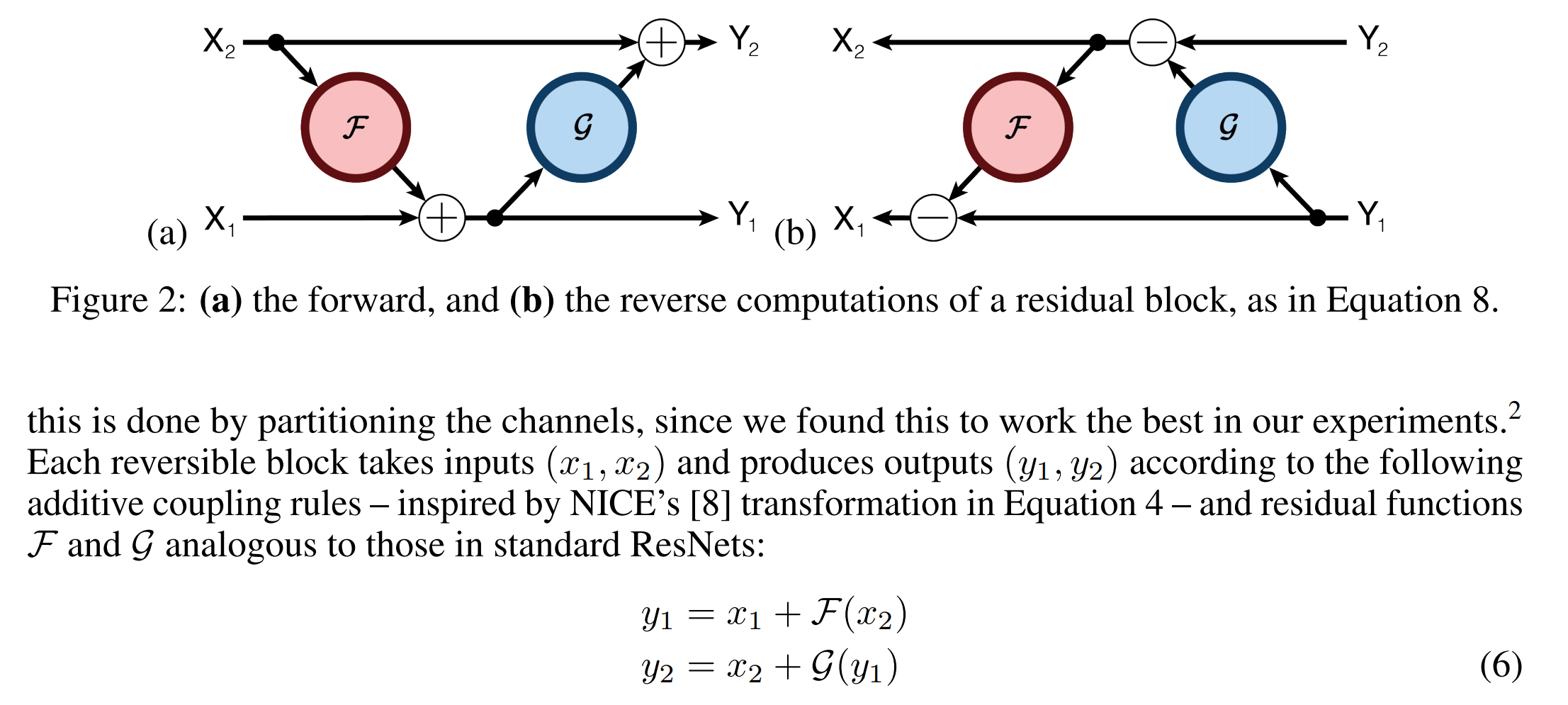
主要想法是每一层的activations可以根据下一层的activations推出来,这样就不需要存储中间的activations。普通的残差形式为,那么一对可逆层作用域一对输入有输出如:,就有如下等式:
那么可以推导得到:
可逆Transformer 应用RevNet想法于Transformer,原本sub-encoder block中的注意力层和前馈层是通过ResNet连接的,将其转换为RevNet。就是说把F变成注意力层,G变成前馈层。注意Layer Normalization 是移到残差块里面的:
可逆Transformer不需要存储每层的激活值就去掉了项。在第5部分,展示了其表现和同样参数的普通Transformer一样,就是让和都是大小来实现。
Chunking 尽管可逆性消掉了项,变薄的网络层仍然要大量的内存。前馈层的维度会非常大如甚至更大。但是,跨位置序列里FFN计算是完全独立的,完整的FFN计算可分成块:
这层通常通过对所有位置并行执行来批量化,但一次一块可以减少内存。可逆计算如公式8以及其反向传播也是分块的。除了前馈层,还对大词汇表的模型(超过单词类型)在输出时的对数概率计算分块,并一次性计算序列各部分的损失。
Chunking, 大批次和参数复用 用分块和可逆层,作者在整个网络中activations占用内存与网络层数无关、尽管参数的数量随着层数的增加而增加,但参数并非如此。这个问题得到解决,因为作者可以在该层不计算时让CPU与内存交换该层的参数。在标准Transformer里,这是非常低效的因为内存转移到CPU中非常慢。然而,Reformer中batch size乘以长度非常大,因此用参数完成计算分摊了转换的成本。
后面部分就是些实验设置和结果了,就不翻译了。
Inference
[2] 论文阅读笔记reformer
[3] Reformer 详解
 wechat
wechat alipay
alipay