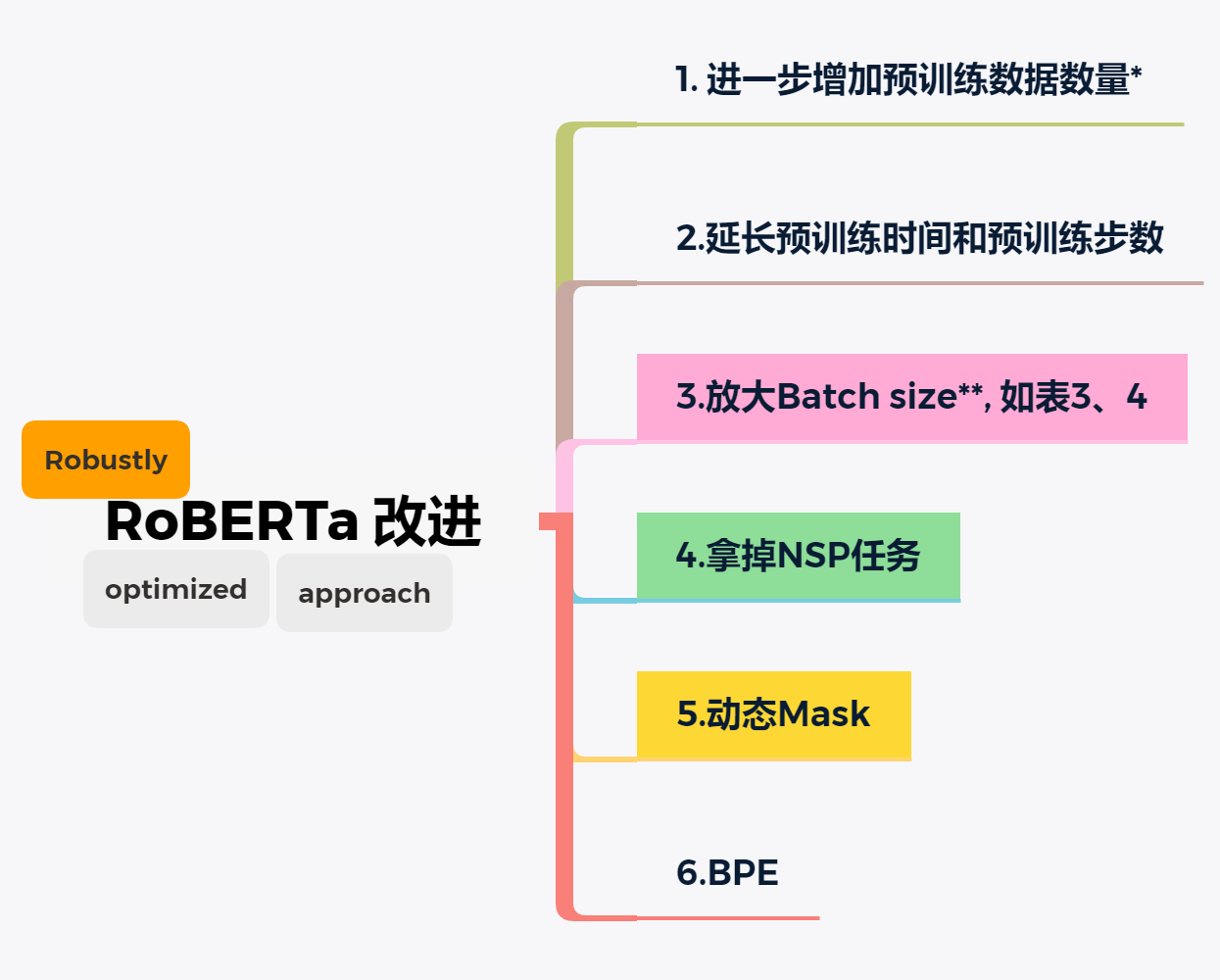
15. RoBERTa 论文笔记
15. RoBERTa 论文笔记
RoBERTa是RoBERTa: A Robustly Optimized BERT Pretraining Approach的简称。本文主要是论文的阅读笔记。
Abstract
预训练语言模型已经取得了显著的表现但是仔细比较不同方法是有挑战性的。在计算上训练非常昂贵,通常在不同大小的私有数据集上,并且超参数选择对最终结果有重大影响。作者提出一个BERT预训练的复制研究,仔细衡量许多关键超参数和训练数据大小的影响。作者发现BERT明显训练不足,并且能匹配和超越在其之后发布的每个模型表现。作者最好的模型在GLUE, RACE 和SQuAD上获得了最佳成绩。这些结果强调之前忽略的设计方案,并提出了近期报告的改进的来源的问题。作者发布了作者的模型和代码。
1. Introduction
自训练方法如ELMo, GPT,BERT, XLM, XLNet已经带来显著的性能提升,但是它们都被质疑,能否准确算出哪些方法贡献最大。在计算上训练是昂贵的,限制了可以进行微调的数目,或者说经常在不同大小的私有数据集上进行,限制了衡量建模效果的能力的发展。
作者提出BERT预训练的复制研究,包含慎重的超参数微调和训练集大小的影响评估。作者发现BERT是显著地训练不足,并提出一个改进的用来训练BERT模型的方案,作者称之为RoBERTa, 其能匹配或超越所有post-BERT方法的性能。作者改进非常简单,它们包括:
- 训练模型更长时间,更大batch_size, 更多的数据
- 移除next sentence预测任务
- 训练更长的句子
- 动态改变应用于训练数据的掩码模式
作者也收集一个新的大型新闻数据集(CC-News) ,其大小类似于其它私人使用的数据集,以便更好地控制训练数据集大小的影响。
当控制训练数据时,作者改进的训练程序提升了已公布的BERT在GLUE和SQuAD两者上的的成绩。当在更多数据上进行更长时间的训练后,RoBERTa在公共GLUE排行榜上获得了88.5的分数,与Yang (Xlnet 2019) 88.4成绩相当。作者模型在4/9的GLUE任务上获得了最佳的成果: MNLI, QNLI, RTE 和STS-B。作者也在SQuAD和RACE上获得了相当的成绩。总的来说,作者重建了BERT的掩码语言模型训练方法和其它最近提出的有竞争性训练方法,如扰动自回归语言模型。
总的来说,本论文的贡献有:
- 作者提出了一组的重要的BERT设计方案和训练策略,并引入更好的下游任务性能的替代方案;
- 作者使用一个小说数据集,CC-News,来确保使用更多数据进行预训练来进一步提升在下游任务上的表现;
- 作者训练提升表明掩码预训练语言模型,在正确的设计方案下,跟近期发布的所有其它方法都具有竞争力。
作者发布了用Pytorch实现的模型,预训练和微调代码。
2. Background
本节,简洁回顾BERT预训练方法和一些作者将在接下来小节中实验检查的训练方案。
2.1 Setup
BERT 采取两段(字符序列)连接作为输入,。字符段通常由多余一个自然语句构成。两个字符段表示为一个用特殊字符分割两者的单一输入序列给BERT:。 其中限制为,而是训练中控制最大序列长度的参数。
该模型是首次预训练在大规模无标签文本语料并随后使用最终任务的有标签数据微调。
2.2 Architecture
BERT使用现在十分普遍的transformer架构,其作者将不会回顾其细节。作者使用层的transformer架构。每个块使用A个维度为H的隐藏层的自注意力头。
2.3 Training Objectives
在预训练期间,BERT使用两个方法:掩码语言模型MLM和下一句预测NSP.
Masked Language Model (MLM)
在输入序列中随机采样选择字符并替换其为特殊的字符[MASK]. MLM目标函数是预测这些mask的 tokens的交叉熵损失。BERT 统一地将输入tokens按15%可能性作为被选择字符进行替换。被选择的80%用[MASK]替换, 10%不变,10%用词汇token中随机选择替换。
在原本实现中,随机选择掩码和替换只在开始执行一次,并将其保存在训练时用;然而在实际中,数据是复制的所以掩码对于每次训练的句子来说不总是一样的。
Next Sentence Prediction(NSP)
NSP 是关于预测在原始文本中的两个字符段是否是跟在一起的二分类损失。正阳样本通过从文本语料库中抽取连续的句子创建。负样本从不同文档中通过取成对片段来创建。正负样本都以同样的概率采样。
NSP目标被设计为用来提升在下游任务的表现,像自然语言推断NLI,需要推理出成对句子间的关系。
2.4 Optimization
BERT 用Adam来优化,参数如下,其权重衰减率为. 学习率预热在前10,000步达到峰值,然后线性衰减。BERT以0.1的dropout在所有层和注意力权重,以及高斯误差线性单元GELU激活函数训练。模型以最大长度为T=512字符序列,mini-batches为预训练步迭代。
2.5 Data
BERT 在BOOKCorpus+英文WIKIPEDIA组合文本上训练,其包含总共16GB压缩文本。
3. Experimental Setup
在本节中,作者描述作者的BERT复制研究实验设置。
3.1 Implementation
作者在 FAIRSEQ 上再现BERT.基本上遵循原始的在小节2 中给定的BERT优化参数,除了峰值学习率lr和预热步数,它们都在每个设置中分开地第微调。 作者额外发现训练对Adam epsilon项非常敏感,并且在一些具体情况中作者在微调它后获得更好的表现或稳定性。类似地,作者发现设置在大的batch size上提升了稳定性。
作者用最大为T=512字符的序列进行预训练。不同于BERT 2019,作者没有随机插入短序列,并且作者不在前90%更新步数中减少序列长度。作者仅训练完整长度的序列。
作者用混合精度的浮点运算在DGX-1机器上训练,每台机器有8x32GB NVIDIA V100 GPUs,其通过无限带宽互连。
3.2 Data
BERT-style 预训练严重依赖大量的文本。Baevski[2019 Cloze-driven Pretraining of Self-attention Networks] [完型填空驱动的预训练自注意力网络, 用类似英语完型填空的方法,对Transformer模型进行预训练] 论文证明增加数据集能提升在最终任务的性能。一些努力已经在比原始BERT更大更多样性的数据集上尝试了。不幸的是, 不是所有额外的数据集都会发布。对于作者研究而言,作者关注于为实验尽可能收集更多数据,允许作者为每次比较匹配整体数据质量和数量。
作者考虑5个不同大小和领域的英语语言语料库,总共超过160GB压缩文本。作者使用如下文本语料库:
- BOOKCORPUS 加 英文维基百科。这就是原始BERT使用的数据(16GB)。
- CC-News, 本论文收集于CommonCrawl News英文部分数据集。其包含63百万爬取与2016年9月到2019年2月的新闻文章 (76GB 在过滤后)。
- OPENWEBTEXT, 一个开源的娱乐网页文本语料库。文本提取于最少3个赞的Reddit分享链接(38GB)。
- STORIES, 一个包含CommonCrawl 的子类,其过滤后跟威诺格拉德模式故事风格类似的数据(31GB)。
3.3 Evalution
遵循之前的工作,作者在下游任务中使用以下3个基准来评估RoBERTa。
GLUE 通用语言理解评估基准,是9个为评估自然语言理解系统数据集集合。任务被设定为单句分类或者句子对分类。GLUE组织者提供训练集和验证集数据划分,以及一个提交服务器,允许参与者在留出测试数据上评估和比较的排行榜。
对于在小节4中的复制研究,作者报告结果是在对应单一任务训练数据微调预训练模型后的验证集结果。微调流程遵循原始BERT论文。
在小节5,作者额外地报告了源于公共排行榜测试集的结果。这些结果依赖针对几个特点任务的修改版,如在5.1小节中描述的。
SQuAD 斯坦福QA数据集提供一段文本和一个问题。任务是通过从上下文中提取相关范围内容来回答这个问题。作者评估两个版本的SQuAD:V1.1 和V2.0. 在V1.1版本中上下文只是包含答案,然而V2.0一些问题就不在提供的上下文中,这使得该任务更有挑战性。
对于SQuAD V1.1 作者像BERT采用一样范围的预测方式。对于V2.0,作者添加额外二值分类器来预测该问题是否有答案,作者通过将分类和范围跨度损失项相加来联合训练。在评估阶段,只预测哪些分类是有答案的成对的范围跨度索引。
RACE 阅读理解数据集,是大规模阅读理解数据集,包含超过28,000文章和将近100,000问题。数据集从中国英语考试中收集,其被设计用来作为初中和高中学生考试题。在阅读理解数据集中,每篇文章和多个问题联系在一起。对于每个问题,任务是从四个选择中选择一个正确的。RACE有大量的比其它流行的阅读理解数据集长的上下文本,并且需要推理的问题占比是非常大的。
4. Training Procedure Analysis
本节探索和量化哪些方案对于成功预训练BERT模型是重要。作者保持模型架构是固定的。特别地,作者开始用如同样配置来训练BERT模型。
4.1 Static vs. Daynamic Masking
如小节2中讨论的,BERT依赖随机掩码来预测tokens。原始BERT实现是在数据预处理时执行掩码一次,造成单一的静态掩码。为了避免在每epoch的每个训练实例上使用同样的掩码,训练数据被复制10份以便每个序列在超过40轮训练中是由10种不同方式掩码而成的。因此,每个训练序列在训练期间看起来是由4次相同的掩码构成的。
作者和动态掩码比较该策略,动态掩码是每次“喂”序列到模型是生成掩码模式。这在对多步预训练或者使用大数据时变得至关重要。
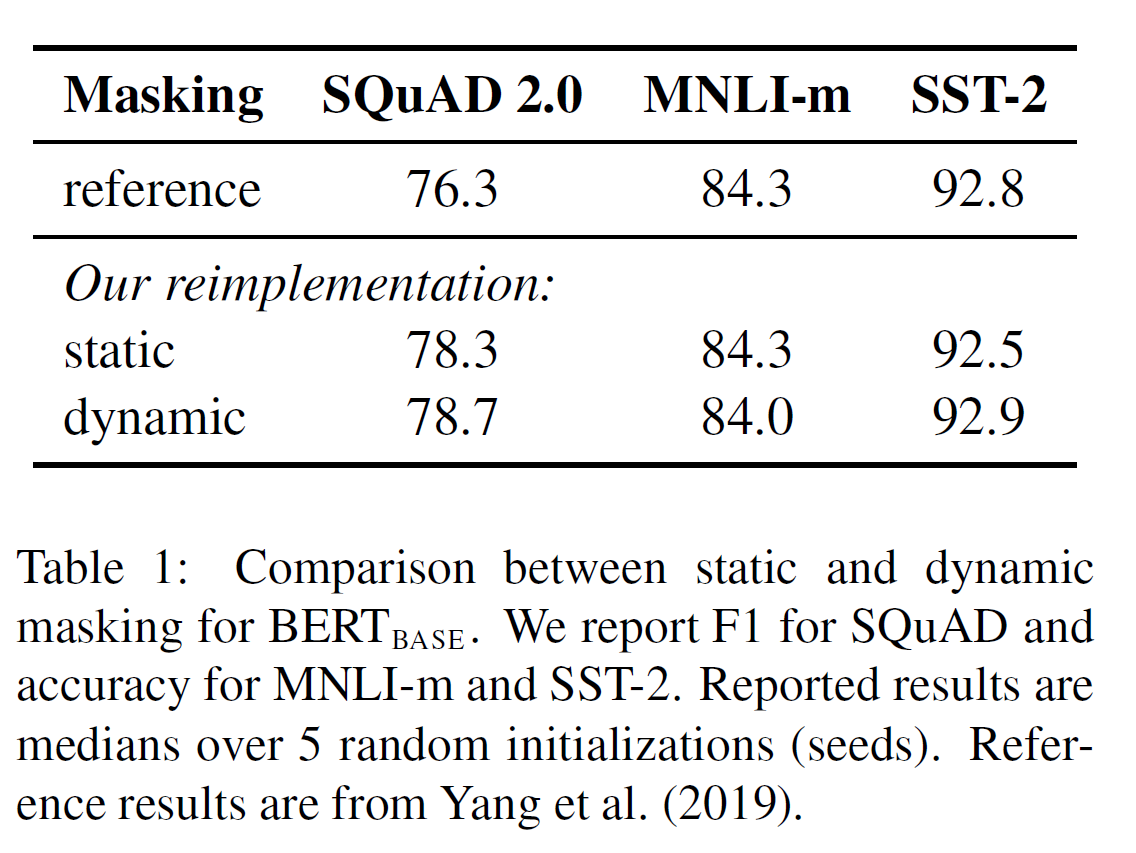
结论 如上表1,和发布的 结果相比,作者用静态和动态掩码复现该结果。作者发现用静态掩码复现的表现类似于原始的BERT模型,但动态掩码轻微好于静态掩码。
给出动态掩码的结果和额外的效率好处,作者在剩下的实验中使用动态掩码。
4.2 模型输入格式和下一句预测
在原始的BERT预训练流程中,模型观测两个文档片段的连接,这两个片段要么是连续从同一文档中采样(p=0.5),要么是从不同文档中采样。加上掩码语言模型目标,该模型训练通过一个辅助的下一句预测损失来预测是否被观察的文档片段来自于同一或不同文档。
NSP 损失在训练原始BERT模型被假设为一个非常重要的因子。Devlin 观察移除NSP任务会影响表现,在QNLI,MNLI,和SQuAD 1.1上有显著的表现退化。然而,近期一些工作质疑NSP 损失的必要性 [Cross-lingual Language Model Pretraining——Lample 2019]。
为了更好理解该差异,作者比较几种可替换训练格式:
- SEGMENT-PAIR + NSP :这个遵循原始BERT使用格式,采用NSP loss. 每个都是成对的片段输入,这样每个输入都包含多个自然语句,但总长度必须小于512。
- SENTENCE-PAIR + NSP : 每个输入包含一个自然语言句子对,这个句子对要么从一个文档部分中连续采样而来,要么就采样自不同文本。因为这些输入明显小于512字符长度,作者增加batch size以便字符总数保留类似于SEGMENT-PAIR + NSP。训练还是用NSP loss。
- FULL-SENTENCES : 每个输入由连续采样自同一文档或多个文档完整句子打包而成,另外总长度最大为512字符。这个输入可能跨文档。当作者到文档结尾时,作者开始从下一个文档中采样,并在两个文档间添加额外的分割符。训练移除NSP loss。
- DOC-SENTENCES : 输入构建类似于FULL-SENTENCES,处理其不跨文本采样。输入采样接近文档末尾还小于512字符,那么作者动态地在这些实例中增加batch size来达到和FULL-SENTENCES总的字符数目是相似的。训练移除NSP loss。
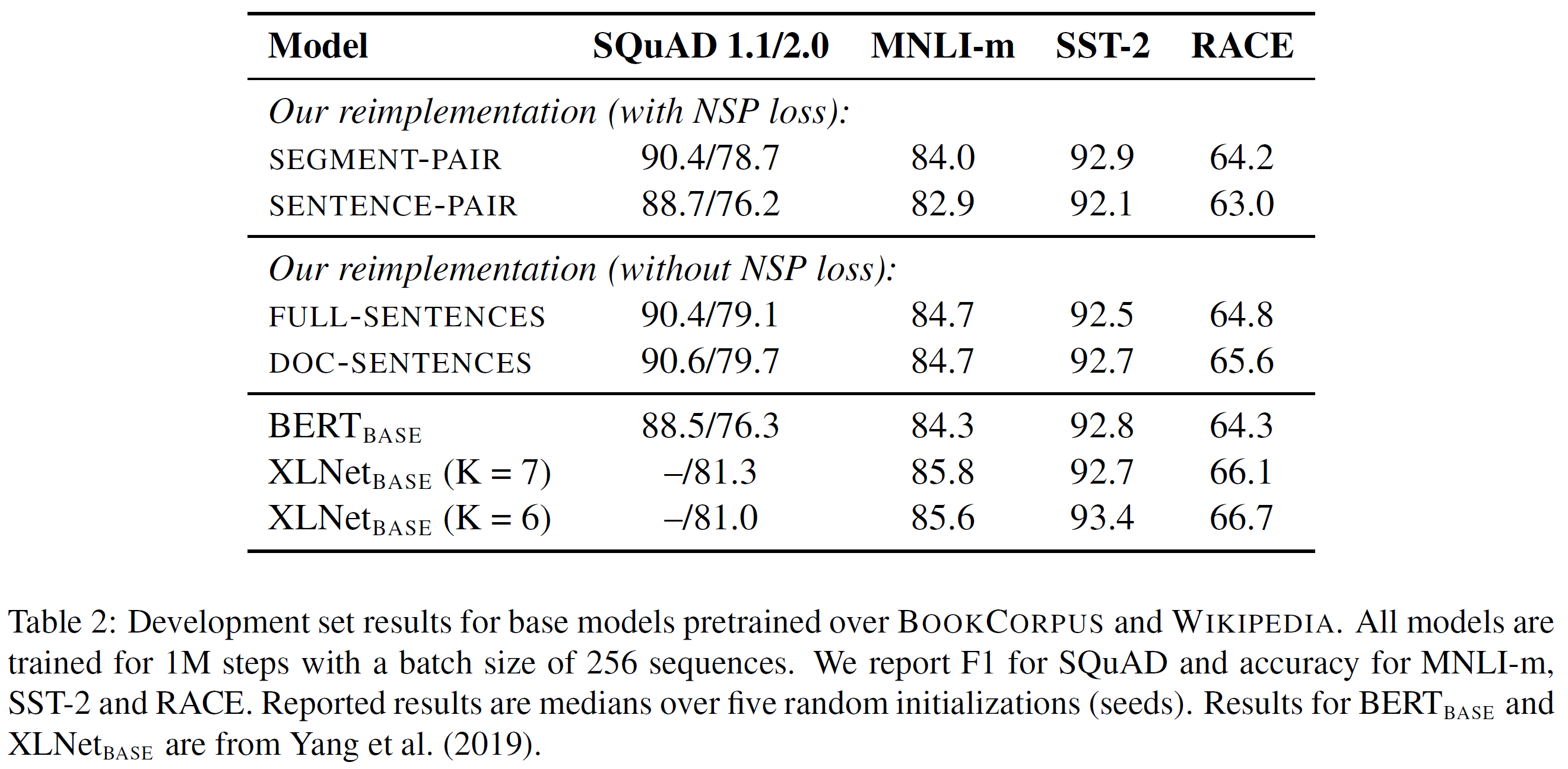
结论 如上表2所示4种不同设置的结果。作者开始拿原始的SEGMENT-PAIR 输入格式和SENTENCE-PAIR格式比较,都保留NSP loss,但最终都使用单一句子。发现使用单独句子让其在下游任务中表现变差,这使得作者假设是因为模型无法学到长距离依赖信息。
作者接下来比较没有NSP loss和用单一文档(DOC-SENTENCES) 形成的文本块训练。发现该设置表现优于原始发布的结果并且移除NSP 任务不太影响下游任务表现,这是跟BERT [2019]对比。这种现象可能是原始BERT实现可能仅仅移除了损失项却仍然保留SENTENCE-PAIR输入格式。
最后作者发现限制输入序列来自于单一文档(DOC-SENTENCES)表现轻微好于从多个文档打包形成的输入(FULL-SENTENCES)。然而,因为这些DOC-SENTENCES格式结构是变化的batch sizes,为了更容易与相关工作比较,作者使用FULL-SENTENCES在剩下的实验中。
4.3 Training with large batches
在神经网络翻译的过去工作中,表明用非常大的小批次mini-batches能提升优化速度和最终任务的表现,当然学习率要恰当地增长。近期工作表明BERT也服从大的batch 训练方式。
原始训练1M 步, 每批为256的序列。在计算成本上相当于,通过梯度累积用每批为2K的序列训练125K 步或每批为8K的序列训练31K步。
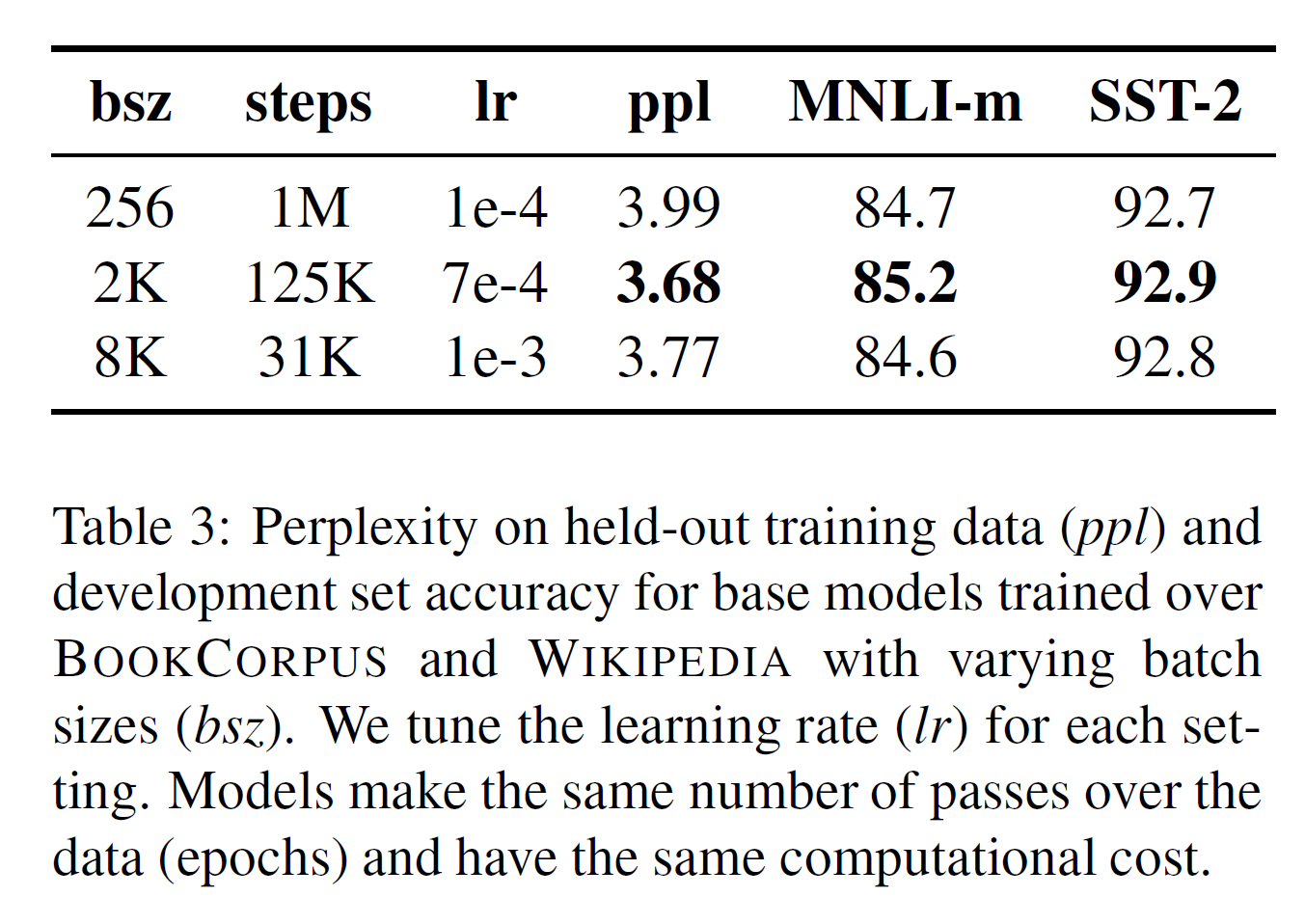
如上表3所示, 作者跟比较困惑度和最终任务表现, 随着每批大小增加,就是控制流入的训练数据数目。观察到用大批次训练会提升掩码语言模型目标的困惑度,也会提升最终任务的准确率。大批次数据也更容易用分布式数据系统来并行化训练,在接下来的实验中,作者用每批8K的序列来训练。
尤其是 You [Reducing bert pre-training time from 3 days to 76 minutes] 用更大的批次数据训练BETR,达到32K序列。作者留给将来工作探索大批次训练的限制。
4.4 Text Encoding
Byte-Pair Encoding(BPE) 字节对编码是介于字符级和单词级的混合表示,可以处理大规模自然语言语料库中的常见的词汇。BPE依赖subwords子词单元而不是完整单词,子词单元可以用统计分析训练语料库得到。
BPE词汇表大小通常在10k-100K子词单元。然而,对大规模和多样语料库建模时,unicode字符占了大部分,例如 Radford 2019GPT-2 Language Models are Unsupervised Multitask Learners 考虑了其工作原因。GPT-2 引入了一个简单BPE实现,使用直接代替unicode 字符作为基本子词单元。使用自己使得其可能学到不太大(50 K units) 子词词汇表,其仍然能在不引入然后“未知”字符条件下编码任意输入文本。
原始BERT实现使用一个字符级别的30K的BPE词汇表,其是在用启发式字符化规则预处理输入后学习得到的。根据Radford 2019 GPT-2中,考虑用字节级别50K子词单元的BPE词汇表训练BERT,而不是用任何额外的预处理或字符化输入。对应着和会增加大约15M和20M额外训练参数。
基于 char-level :原始 BERT 的方式,它通过对输入文本进行启发式的词干化之后处理得到。
基于 bytes-level:与 char-level 的区别在于bytes-level 使用 bytes 而不是 unicode 字符作为 sub-word 的基本单位,因此可以编码任何输入文本而不会引入 UNKOWN 标记。 ——RoBERTa 笔记
早期实验显示这些编码直接只有轻微差异,在Radford 2019 GPT-2 BPE的一些任务上得到更长的最终任务表现甚至稍差。尽管如此,作者相信统一编码方案的优势超过性能轻微下降。更多这些编码的细节比较将留给未来工作。
5. RoBERTa
在之前的小结中作者提出对BERT预训练流程进行修改来提升最终任务表现。现在合计这些改进和评估它们共同的影响。作者把这些配置叫做RoBERTa,即Robustly optimized BERT approach 强壮的BERT优化方法。特别地,RoBERTa用动态掩码(4.1节)训练, 没有NSP loss的FULL-SENTENCES 输入(4.2节),大的mini-batches(4.3节)以及大规模的字节级编码BPE(4.4节)。
另外地,作者研究两个其它重要的因素,在之前工作中没有被强调的:
- 用于预训练的数据
- 训练步数
例如,近期提出的XLNet架构,预训练数据接近原始BERT的10倍。其用8倍的batch size, 优化步数减半训练,因此看起来是BERT4倍的预训练序列。
为了从其他模型方案中(如, 预训练目标)帮助理清这些因素的重要性,开始时使用架构的配置L=24, H=1024,A=16, 355M参数来训练RoBERTa。在一个类似的BOOKCORPUS+WIKIPEDIA数据集预训练100K步,这也用于BERT Devlin 2019 .整个预训练使用1024 块V100 GPUs 将近一天。

结论 如上表4所示, 当控制训练数据时,观察到RoBERTa相比原始报告的有大的提升,再次肯定了作者在小节4中提到的设计方案的重要性。
接着,联合3个小节3.2中附加的数据集和BOOK + WIKI数据。并用跟之前一样训练步数(100K)在联合数据上训练RoBERTa。总共预训练数据文本超过160GB。进一步观察其在所有下游任务的性能提升,验证数据大小和多样性在预训练中的重要性。
最后, 预训练RoBERTa 步数显著变长,预训练步数从100K到300K,最后进一步到500K。作者再次观察在下游任务上获得显著性能提升,在大部分任务上300K到500K步训练的模型性能优于.注意到更长时间训练模型没有在作者的数据上出现过拟合,而从额外训练中获益。
在剩余的本文中,在3个不同基准上评估最好的RoBERTa模型,分别是GLUE, SQuAD和RACE。特别地,作者考虑在小节3.2中介绍的5个数据集上训练500K步。
5.1 GLUE Results
对于GLUE,作者考虑两个微调设置。第一个设置(单一任务, 验证),对每个GLUE任务分别微调RoBERTa,这仅使用对应任务的训练数据。作者考虑限制超参数扫描每个任务,如batch size 为{16, 32}, lr为{1e-5, 2e-5, 3e-5}, 在开始的6%不是线性预热接着线性衰减到0.微调10轮,并基于每个任务验证集评估标准执行早停。剩下的超参数在预训练时保持不变。在该设置中,在每个任务上的5个随机初始化模型在验证集上结果的中位数作为报告,并且没有模型集成。
第二个设置(集成, test), 通过GLUE排行榜和其它方法在测试集上比较RoBERTa。然而许多排行榜上结果依赖多任务微调,作者提交只依赖与单一任务微调。对于RTE,STS以及MRPC,发现其对微调帮助其余MNLI单一任务模型,而不是预训练RoBERTa的基线。作者探索一个稍宽的超参数空间,如附录,并在每个任务上组合5到7个模型。
具体任务修改 两个GLUE任务需要特定任务的微调方法来达到有竞争性的排行榜结果。
QNLI (Qusetion-answering NLI,问答自然语言推断): 对于QNLI任务最近提交在GLUE排行榜采用成对的答案计算排名,就是候选答案挖掘于训练集并和另一个比较,一个单一的(问题, 候选答案)对被分类为正例。该计算公式明显地简化了盖伦肉,但不是直接对比于BERT。遵循最近工作,作者对测试提交采用该排名方法,但为了直接和BERT比较,报告中验证集结果基于纯粹的分类任务。
WNLI (Winograd NLI,Winograd自然语言推断): 作者发现提供的NLI-format数据很难处理,反而作者使用从Super GLUE [Wang 2019 A stickier benchmark for general-purpose language understanding systems]中重新格式化后的WNLI数据,其表示查询词和所指对象的范围。作者使用边缘排名损失来微调RoBERTa,来自于[Kocijan 2019 A Surprisingly Robust Trick for the Winograd Schema Challenge]。作者使用spaCy来提取来自句子中的额外的候选名词词组并微调作者模型让其对正向相关词组比生成的任意的负向候选词组分配高分数。该计算方式不好的结果是作者只能利用正训练样本,这只包括超过一半提供的训练样本。
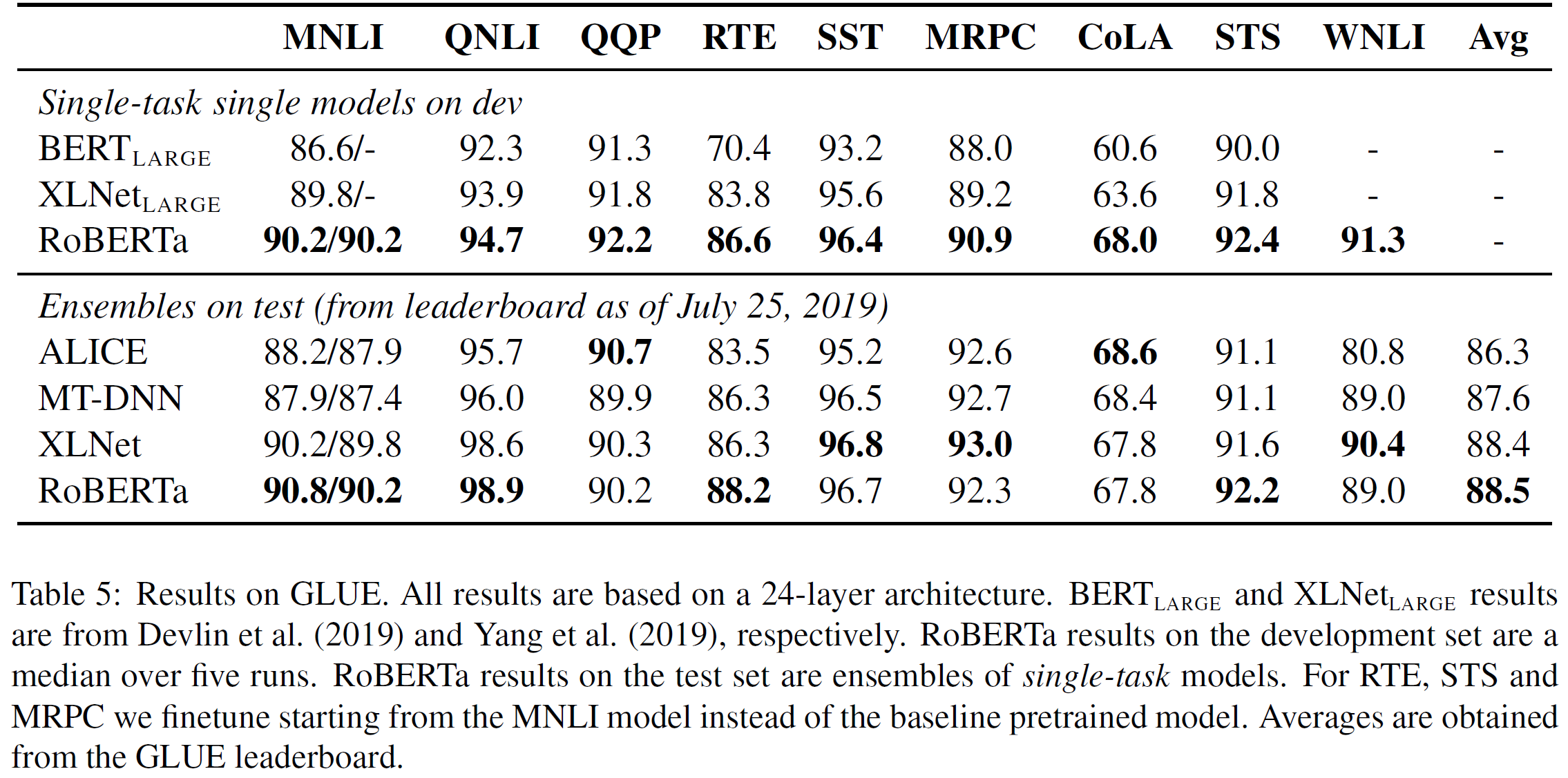
结论 如上表5所示,第一个设置(单一任务, 验证集),RoBERTa在GLUE的9项任务中用验证集取得了最佳成绩。至关重要的是,RoBERTa使用跟一样的掩码语言建模预训练目标和架构,但始终优于和.这引发了有关模型架构和预训练目标,和更平凡的细节如在本文中的研究的数据大小,训练时间哪个更重要的质疑。
第二个设置(集成, 测试集), 作者将RoBERTa提交给GLUE排行榜,并取得了9个任务中4个最佳的成绩及迄今为止的最高平均分。这十分振奋人心,因为RoBERTa不依赖多任务的微调,不像大部分其它的高分提交。作者期望未来工作通过包含更多先决的多任务微调流程更进一步提升这些成绩。
5.2 SQuAD Results
作者相比之前工作对SQuAD采用更简单的方法。特别是,BERT和XLNet通过额外的QA数据集来增加它们的训练数据,作者只用提供的SQuAD数据来微调RoBERTa。Yang 2019 还采用自定义的逐层计划学习率来微调XLNet,而作者在所有层使用同样的学习率。
对于SQuAD v1.1作者跟BERT使用同样的微调方案。对于V2.0, 作者添加给定一个问题是否可回答的分类任务;通过对该分类和预测范围的损失相加来联合训练分类器和范围预测。
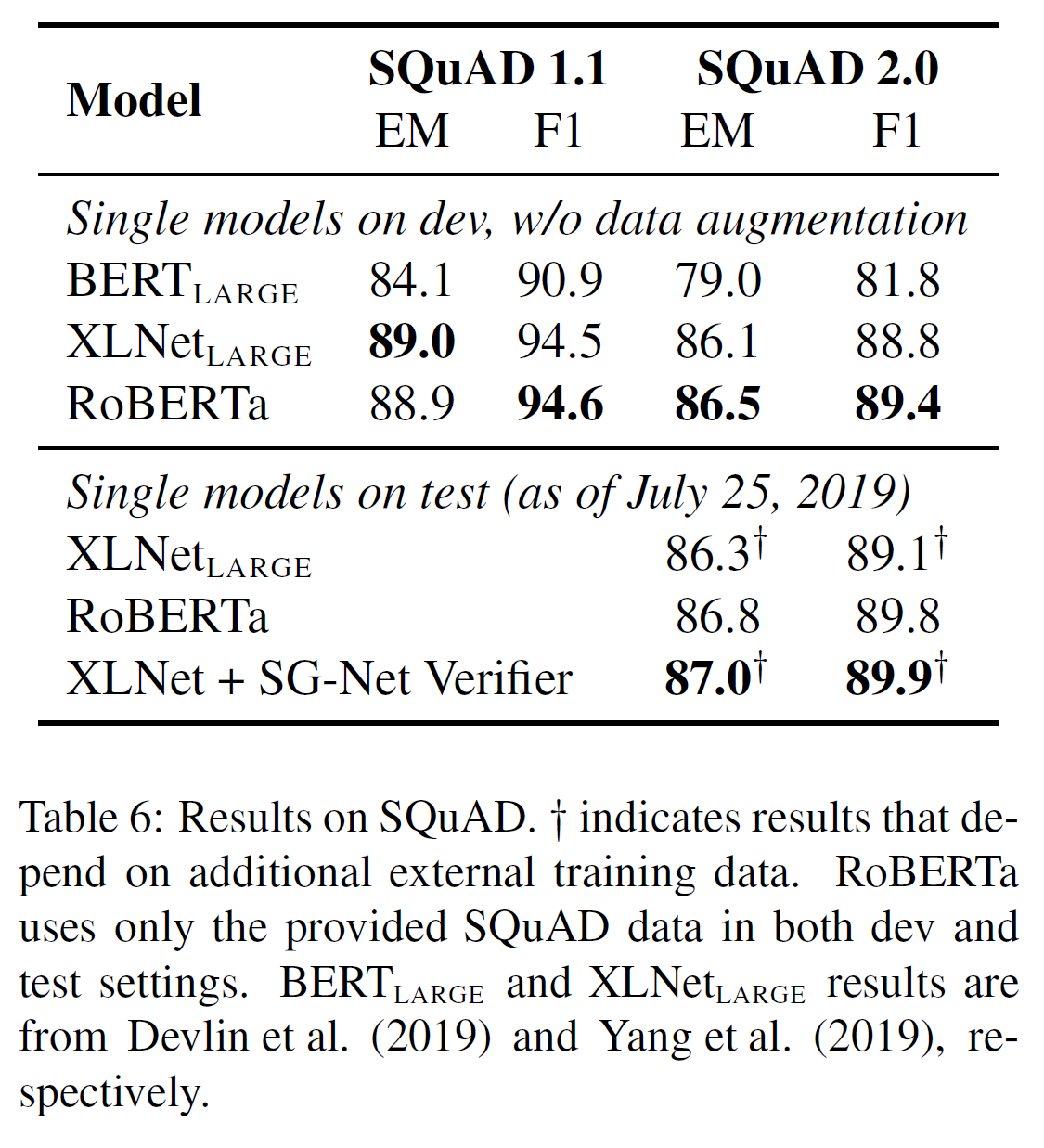
结论 如上表6所示,在SQuAD v1.1 的验证集上,RoBERTa跟XLNet结果差不多。在V2.0验证集上,RoBERTa取得新的最佳成绩,比XLNet提升0.4个点(EM) 和 0.6个点 (F1)。
作者也提交RoBERTa到公共的SQuAD 2.0 排行榜,来评估其相对其它系统的表现。大部分顶层系统要么构建于BERT要么XLNet,两种都依赖于额外训练数据。相反,本文提交不使用任何额外的数据。
单一RoBERTa模型优于其它单一模型的提交,并且是这些模型之间不依赖数据增强的最高分。
5.3 RACE Results
在RACE中,系统提供了一篇文章、一个相关问题和四个候选答案。系统需要区分四个候选答案哪个是正确的。
作者为该任务修改RoBERTa,将每个候选答案与其对应的问题和文章连接在一起。然后编码这四个序列和传递结果的[CLS]表示,流过全连接层,其用来预测正确答案。作者截断那些长于128个字符的问题-答案对,如果需要,截断文章使得总长度最长为512字符。
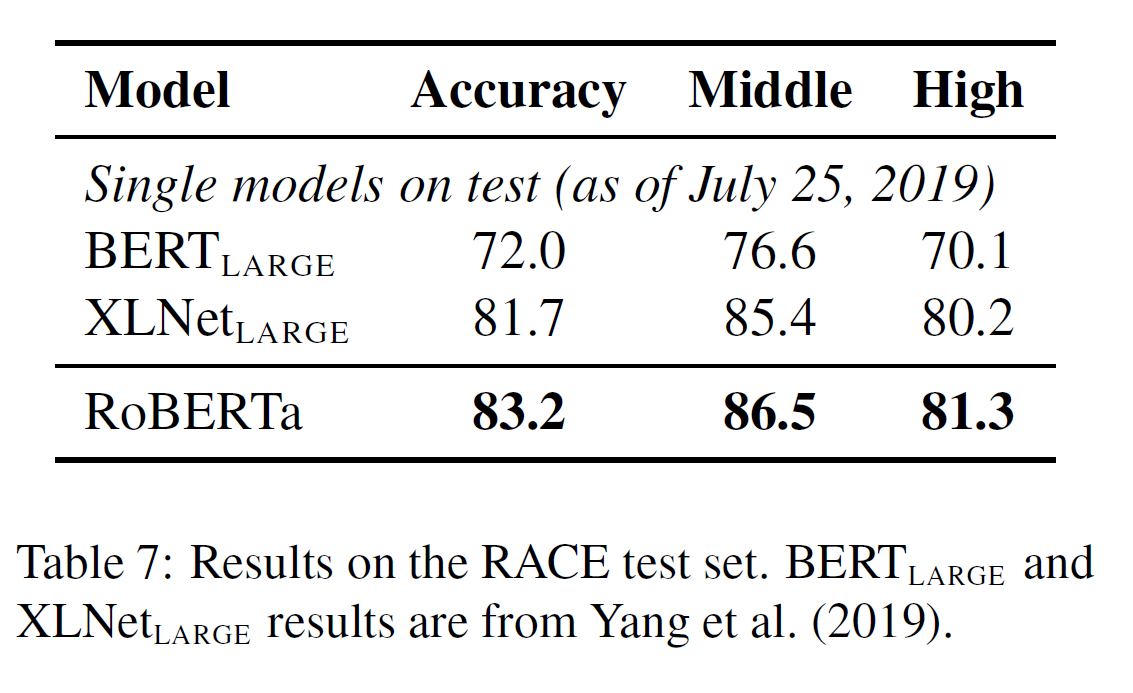
结果如上表7,在RACE测试集上,RoBERTa在初中组和高中组都取得了最佳成绩。
总结
作者仔细评估了一些在预训练BERT模型时的设计方案。发现性能能大大地提升方案:
- 训练更长时间
- 在更多数据上使用大的batch size
- 移除NSP目标
- 训练更长的序列
- 使用训练数据动态改变掩码模型
本文的提升预训练方案,称作RoBERTa,在GLUE,RACE和SQuAD上取得了最佳成绩。
- 在GLUE上没有多任务微调
- 在SQuAD上没有使用额外数据
这些结果证明了之前整体设计方案的重要性和近期提出的可替代方案中建议BERT的预训练目标保留是有竞争力的。
添加的数据有一个小说数据集,CC-News。预训练和微调的模型和代码地址.
Inference
[1] 中文预训练RoBERTa模型
[2] RoBERTa 笔记
[3] RoBERTa论文详解和代码实战
 wechat
wechat alipay
alipay
