31. PET 论文笔记
31. PET 论文笔记
来自 Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference.

开源代码地址 pet.
Abstract
一些NLP任务能用无监督学习的样式解决,通过采用自然语言里“任务描述”的预训练语言模型。尽管这种方法不如监督学习表现,作者展示了在这项工作两点想法的结合:
- PET: Pattern-Exploiting Training, 用半监督学习方法将输入样本设计成完形填空样式词组来帮助语言模型理解指定任务。这些词组然后被用来对大量未标注的样本分配软标签。
- 最后,在训练集上用标准监督学习。
对几个任务和语言,PET表现比监督序列和低资源的强半监督方法都要优秀。
1. Introduction
例如下面3局话,想象下如果知道T1和T2的标签是,接下来,就可以推出T3的标签应该是。
这证明对于语言,如果有一个任务描述,解决小样本分类能简单很多。
tips: task description:就是一段文本,用来帮助预训练语言模型理解任务 。
- T1: This was the best pizza I’ve ever had.
- T2: You can get better sushi for half the price.
- T3: Pizza was average. Not worth the price.
作者展示了,将任务描述成功地和标准监督学习在小样本上结合起来:引入Pattern-Exploiting Training(PET), 用natural language pattern来重新描述输入样本成完形填空样式短语的半监督训练方法。如下图1所示,PET工作流程为3步:
- 对每个模板,在小的训练集上,微调单独的PLM。
- 集成所有的模型,对大型未标注数据集标注软标签。
- 然后在得到的大量未标注的软标签数据集上进行标准分类。
作者也设计了iPET, PET的迭代变种,就是重复上述流程来不断增加训练集规模。
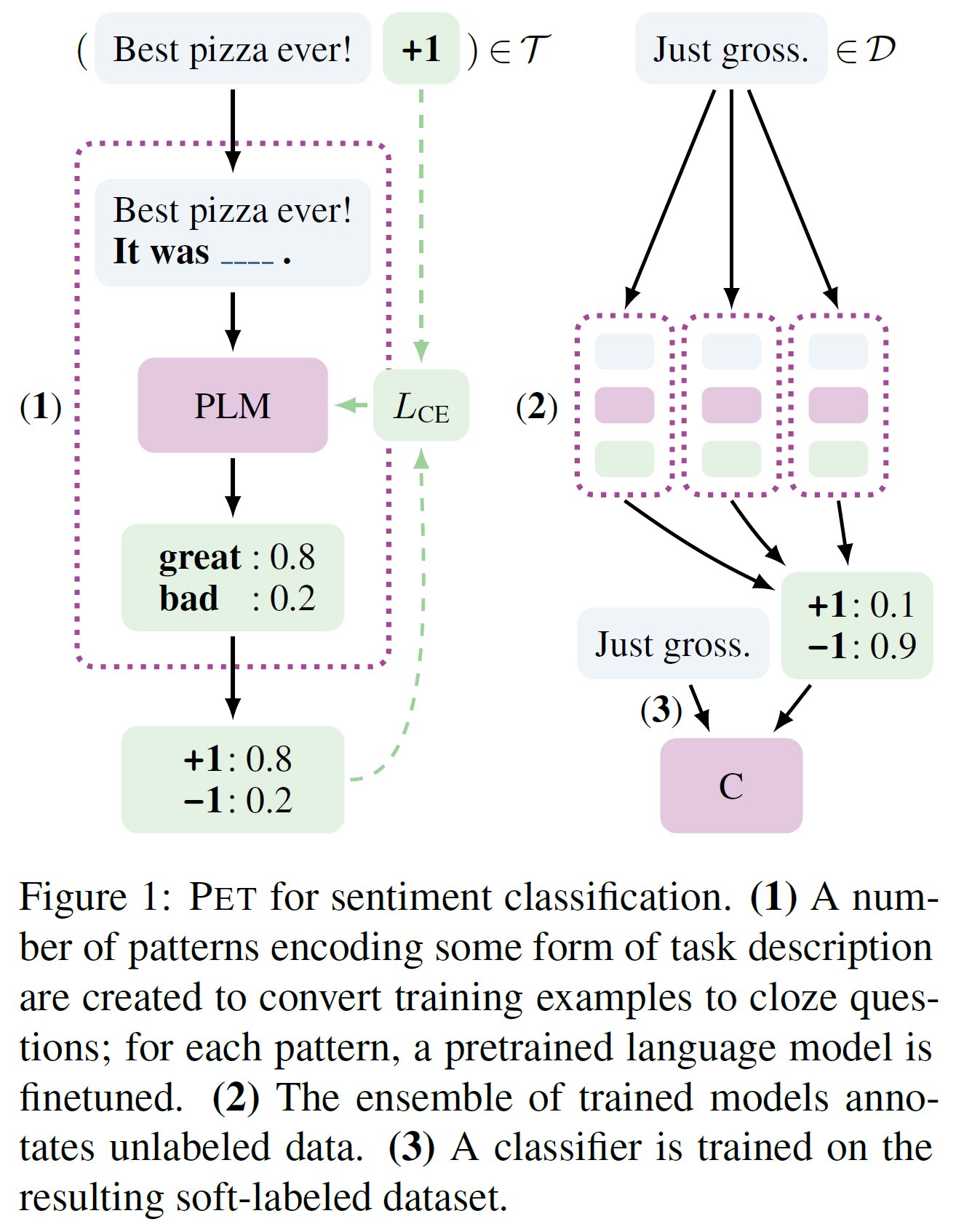
上图1是PET左情感分类。(就是PET工作流程的实例说明。)
- 针对任务描述,设计一些模板将输入样板转换为完形填空问题。比如这里, Best pizza ever! It was _!。拿一种模板对一个PLM进行微调。
- 集成的训练模型标注未标注的数据集得到软标签。
- 在软标签数据集上进行标准分类训练。
3. Pattern-Exploiting Training
定义M为以词汇表V的MLM,并且mask token 。让表示分类任务的标签集合A。改写任务A的输入为一个个短语或句子,。例如,就是有两个句子。
定义pattern为一个函数P, 将输入, 转换为输出包含mask token的短语或句子 , 这就是一个输出的完形填空问题。
定义verbalizera为一个映射函数, 就是映射每个标签到所使用的预训练语言模型的一个词。(bert 家族的预训练语言模型的词就是词汇表里的token)。并且定义作为pattern-verbalizer pair(PVP)。
使用 可以将任务A描述为:
给定输入, 利用P获得输入的表示, 然后用预训练语言模型M处理来判断标签 最可能的mask token。
例如, 判断两个句子a, b是同意还是反对。可以设计pattern 。这样就用verbalizer 将标签分别映射为“Yes”, “No”。比如:
转换为pattern:
总结下,设计一个pattern,将输入 , 转换为输出包含mask token的短语或句子 。这个pattern为函数P。其中token 。verbalizer是映射函数,将标签映射为token。而两种结合起来就叫做pattern-verbalizer pair(PVP)。
3.1 PVP Training and Inference

3.2 Auxiliary Language Modeling
在作者的应用情景中,只有少量训练样本,这样灾难性遗忘可能发生。一些PVP的核心仍然是对PLM微调,作者提出使用语言模型作为辅助任务。
- 用表示交叉熵损失
- 用表示语言模型损失, (bert 类语言模型本身的两大设计任务就是Mask model language 和 Next sentence prediction )
因为一般比大,所以.
为了获取句子进行语言建模,使用未标注数据集。 然而,作者不直接在未标注数据集训练,而是训练, 即从不要求对mask 的槽位进行预测。
3.3 Combining PVPs
关键挑战是缺乏大规模的验证集,无法鉴定哪个PVPs表现好。为了解决这个问题,作者采用知识蒸馏的策略。
- 定义任务A的PVPs的集合为
- 每个LM, 在每个pattern上微调,如3.1节所说,当训练集很小时,即使PVPs很大也很廉价
- 使用集成的微调模型 在未标注数据集上标注。那么将每个样本的非标准化类别分数结合起来有:
这里, 其中是对应PVPs的权重。作者用两个不同的实现来表示权重:
- 将所有设置为1
- 根据训练集长的准确率来设置
然后将上式6中的分数用softmax转换成概率分布q. 根据Hition的知识蒸馏,使用T=2来获得软分布。所有的对构成新的训练集。
- 在得到的训练集上微调得到PLM 模型C.
这个微调的模型C就可以用于分类任务A了。所有步骤如图2所示,样本示例如上图1.
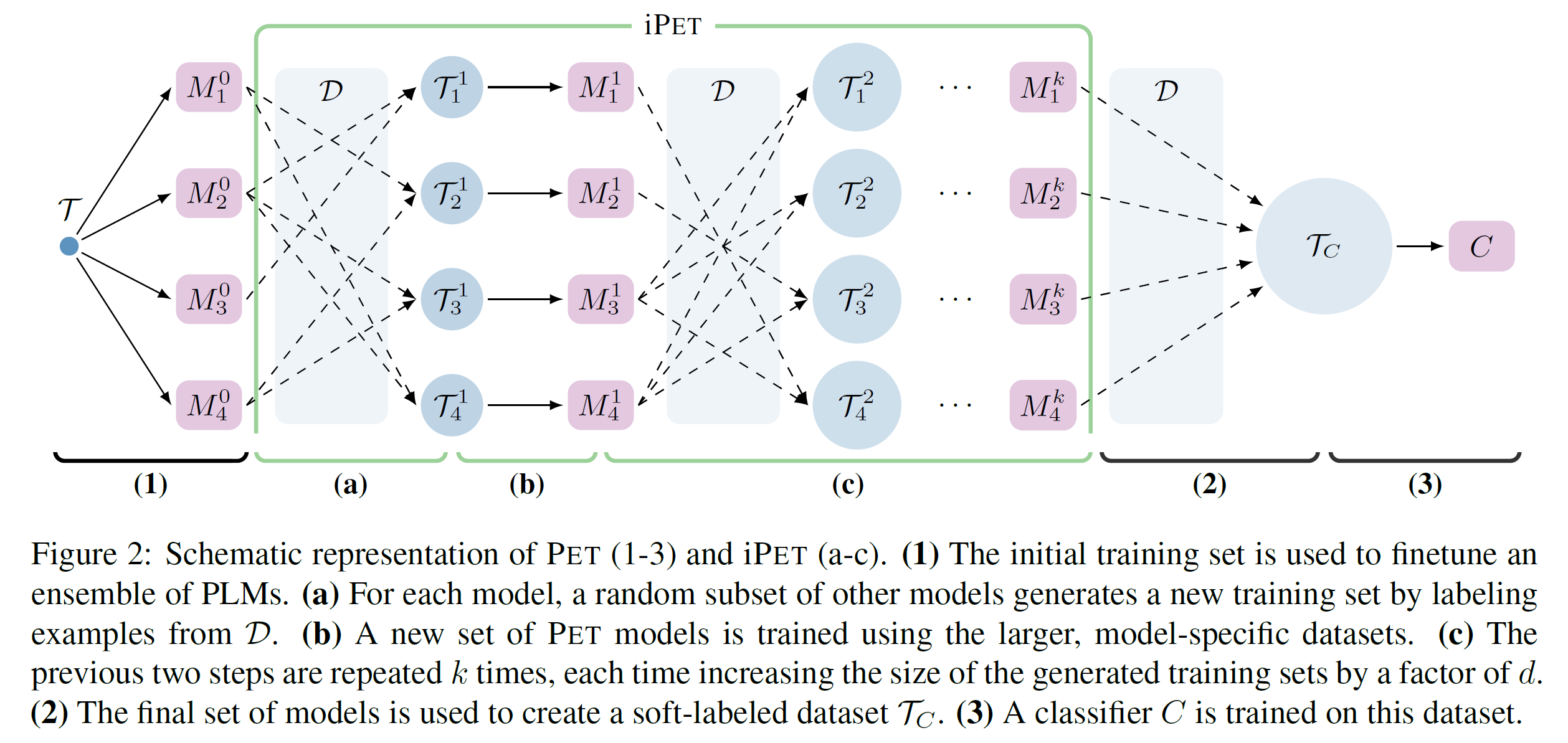
图2中,1-3这个过程是PET简略表示。
(1)初始化训练集来微调一个集成的PLMs
a. 对每个模型,一个随机的其他模型的子集生成新的标注训练集
b.用更大特定模型的数据集训练一个新PET模型集合
c. 重复a, b步k次, 每次通过一个因子d来增加生成训练集的数目。
(2) 最终模型集合来创建软标签数据集。
(3) 在软标签数据集上训练分类器C。
3.4 Iterative PET (iPET)
将所有独立的模型知识蒸馏到一个分类器C意味着它们无法从各自学习。当某些patterns表现上比其它要差时,最终模型的训练集中可能有许多误标注的样本。
为了克服这个缺点,作者设计了iPET, PET的迭代版本。iPET核心想法是在增加的数据集上训练几个生成模型。为此,首先用一个随机的训练好的PET模型子集来标注从数据集的样本来增大原始数据。(如图2a所示)。然后在扩大的数据集上训练新的PET生成模型(如图2b)。这个过程会重复几次。
更正式地,
- 定义表示在训练集上微调的一组PET模型,其中:
表示用PVP中某个训练的模型。
- 训练k代生成模型,其中, 并且每个是在上用其对应的训练集。(这里很绕,关键是表示不同的pattern, 不同pattern会采样不同训练集,而表示迭代的次数,总共k次。)
- 每次迭代,用训练集数目乘以一个固定常数,当然样本标签比例跟原始样本一致。
- 用表示训练集中样本的数目,每个包含类别的数目计算为:。
这些是通过生成每个来实现的,具体如下:
- 从前一代模型中随机选择个模型构成一个子集,记作:。 是一个超参数。
- 使用这个子集来创建标注数据集
式7表示输入样板使得其属于类别l的分数最大化。
对于每个标签,通过随机从训练集选择个l样本来获得。即保证标签类别分布一致,这里表示迭代到第几步。为了避免训练特征生成误分类标签, 选取那些集成模型预测值高的。因此,当从抽取样本后,作者设定每个正比于。
- 定义。即每个都等于原始训练集加上抽取的每个l类样本的数据集。
经过训练k次后,PET模型,作者使用来创建并训练分类器作为基础版本的PET。
为了最小调整,iPET使用零样本设置。为此,定义, 表示没有训练的模型集合。
# Step 1: Train an ensemble of models corresponding to individual patterns
# Step 2: Use the model to annotate examples for the next generation
# Step 3: Merge the annotations created by each individual model
# Step 4: Train the final sequence classifier model
——pet
, 表示第一个pattern的数据集为包含所有样本的10个样本。因为可能不含足够的l类样本,作者通过对分数最高的100个样本采样来创建所有的 , 即使可能类别不是最高的。对后续的每个迭代,都按照这个基本的iPET执行。
 wechat
wechat alipay
alipay