25. NEZHA 论文笔记
25. NEZHA 论文笔记
本文是NEZHA: NEURAL CONTEXTUALIZED REPRESENTATION FOR CHINESE LANGUAGE UNDERSTANDING的笔记。
摘要
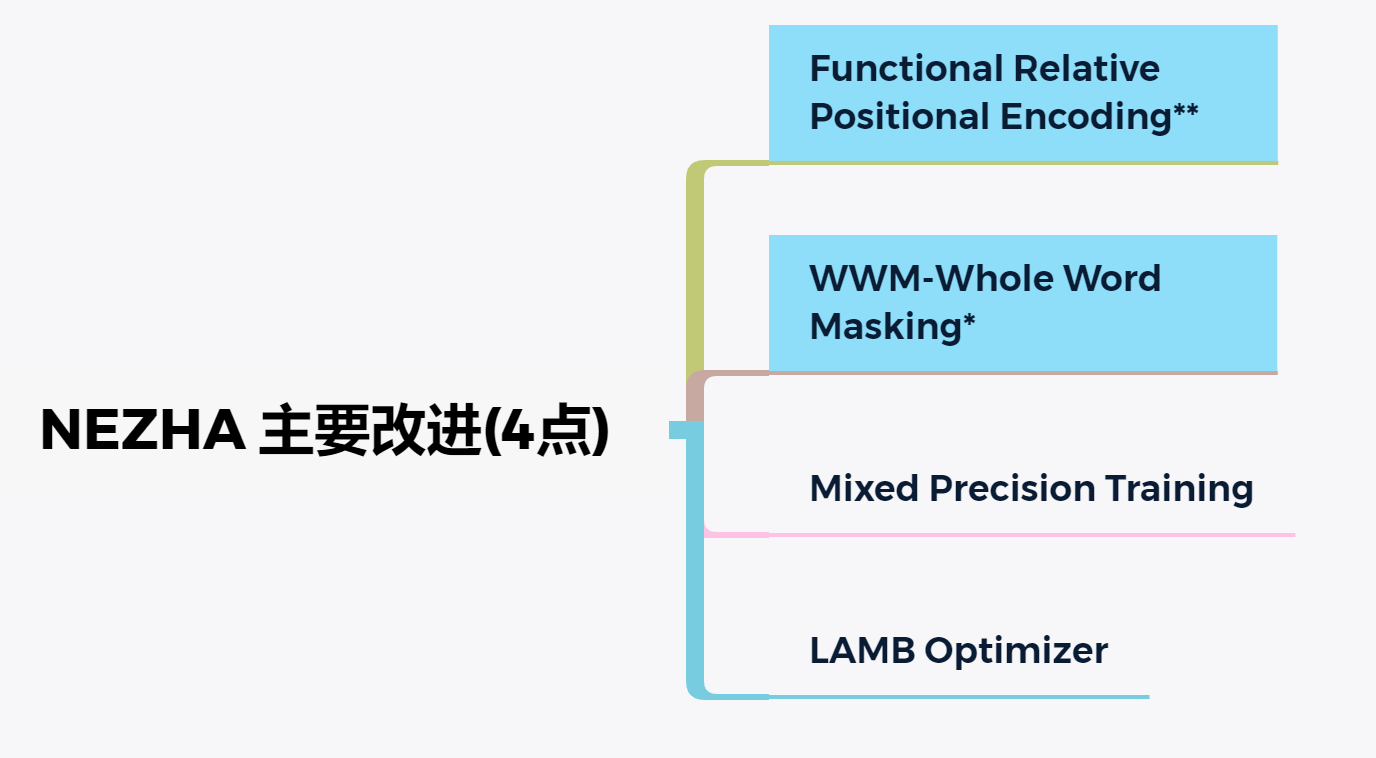
预训练语言模型已经在大量NLU任务上取得巨大成功,这要归功于其在大规模语料上预训练获取的深层上下文信息的能力。本文提出了作者预训练语言模型NEZHA(NEural contextualiZed representation for CHinese lAnguage understanding),其在中文语料上训练然后为中文NLU任务微调。当前版本的NEZHA基于BERT,使用了4项改进措施。包括:
- Functional Relative Positional Encoding 作为有效的位置编码方案
- Whole Word Masking 掩码策略
- Mixed Precision Training 混合精度训练
- LAMB Optimizer 优化器
实验结果表明NEZHA在以下中文任务上微调后取得了最佳的表现:
- 命名实体识别(People’s Daily NER)
- 句子匹配(LCQMC)
- 中文情感分析(ChnSenti)
- 自然语言推断(XNLI)
2. Pre-training NEZHA Models
2.1 Preliminaries: BERT Model & Positional Encoding
BERT(Bidirectional Encoder Representations from Transformers) 是一个预训练模型,就是堆叠Transformer encoder。使用残差连接来连接各个子层,紧接一个normalization。BERT可视为一个去噪自编码器,因为MASK后的MLM任务就是将添加MASK后的词预测出来,即将添加噪声的的data恢复。
来看看Transformer中的具体实现过程,详细过程看transformer笔记.
每个注意力头是对一个token序列如.(这里是一个个的词向量,长为)处理后得到一个输出序列.每个注意力有3个参数矩阵(训练得到):。有这些参数,输出可计算为:
这里要注意注意力分数指位置i相对位置j的隐藏状态过softmax得到即:
对于,它是输入元素的线性变换的点积再放缩下得到的:
因为多头注意力是一种恒定的排列,其对词序不敏感。因此Transformer使用了函数式位置编码,BERT使用了参数式位置编码直接添加到embedding上。这里使用相对位置编码方案,注意力分数计算要包含两个位置相对距离参数嵌入,这里也是将其直接加载embedding上。这样,式1和3中的计算就变成了:
以及:
其中是两个向量,表示相对于位置i和位置j的编码,其跟所有注意力头共享。这里跟Transformer-XL和XLNet有所区别。接下来讲下其是怎么计算的。
2.2 Functional Relative Positional Encoding
在当前版本的NEZHA中,使用函数式相对位置编码,还是由正余弦函数得来,并且模型训练时固定。如果的维度为和 ,那么,
每个维度的位置编码对应着一个余弦,不同维度的有着不同的波长。(周期不同)。是跟模型相关的,就是hidden size/number of heads。波长从到。选择固定的余弦函数主要是因为它可以使得模型推断比训练时遇到的句子更长的序列。
2.3 Whole Word Masking
全词掩码是 Pre-Training with Whole Word Masking for Chinese BERT提出来的,WWM能有效提高预训练语言模型。
WWM:原有基于WordPiece的分词方式会把一个完整的词切分成若干个子词,在生成训练样本时,这些被分开的子词会随机被mask。 在全词Mask中,如果一个完整的词的部分WordPiece子词被mask,则同属该词的其他部分也会被mask,即全词Mask。
2.4 Mixed Precision Training
使用混合精度训练,能提升2-3倍效率,并较少模型空间消耗,根据其结果,大的batch size可以利用它。
为了方便,整个网络使用FP32浮点数,包括训练时模型参数、梯度。混合精度在训练时使用,具体来说,其维持一个单精度的Master Weights的复制(就是模型的权重)。在每轮训练中,将Master Weights精简到FP16,并且前向和反向传播时将其使用在权重,激活和梯度部分。最后将梯度转换成FP32格式,使用FP32梯度更新到Master Weights。
2.5 LAMB Optimizer
在大的batch size中训练模型会给模型的泛化能力带来负面影响,而LAMB优化器通过自适应方式为每个参数调整lr,能够在大batch size下训练,并且能提高训练速度。
3. 实验
预训练语料:
- 中文维基百科: 用WikiExtractor并清洗后大约有202M字符
- 百度百科: 清洗后有4,734M字符
- 中文新闻:多个新闻网站,如新浪新闻,5,600M字符
预训练细节:
10台华为云服务,每台8块32GB的V100GPU。
- NEZHA base模型,最大学习率为1.8e-4(1800预热,线性衰减).总共batch size为180 8 10 = 14400,每个GPU 180 batch size.
- NEZHA large模型,每个GPU batch size设置为64.总共batch size为64 8 10 = 5120.
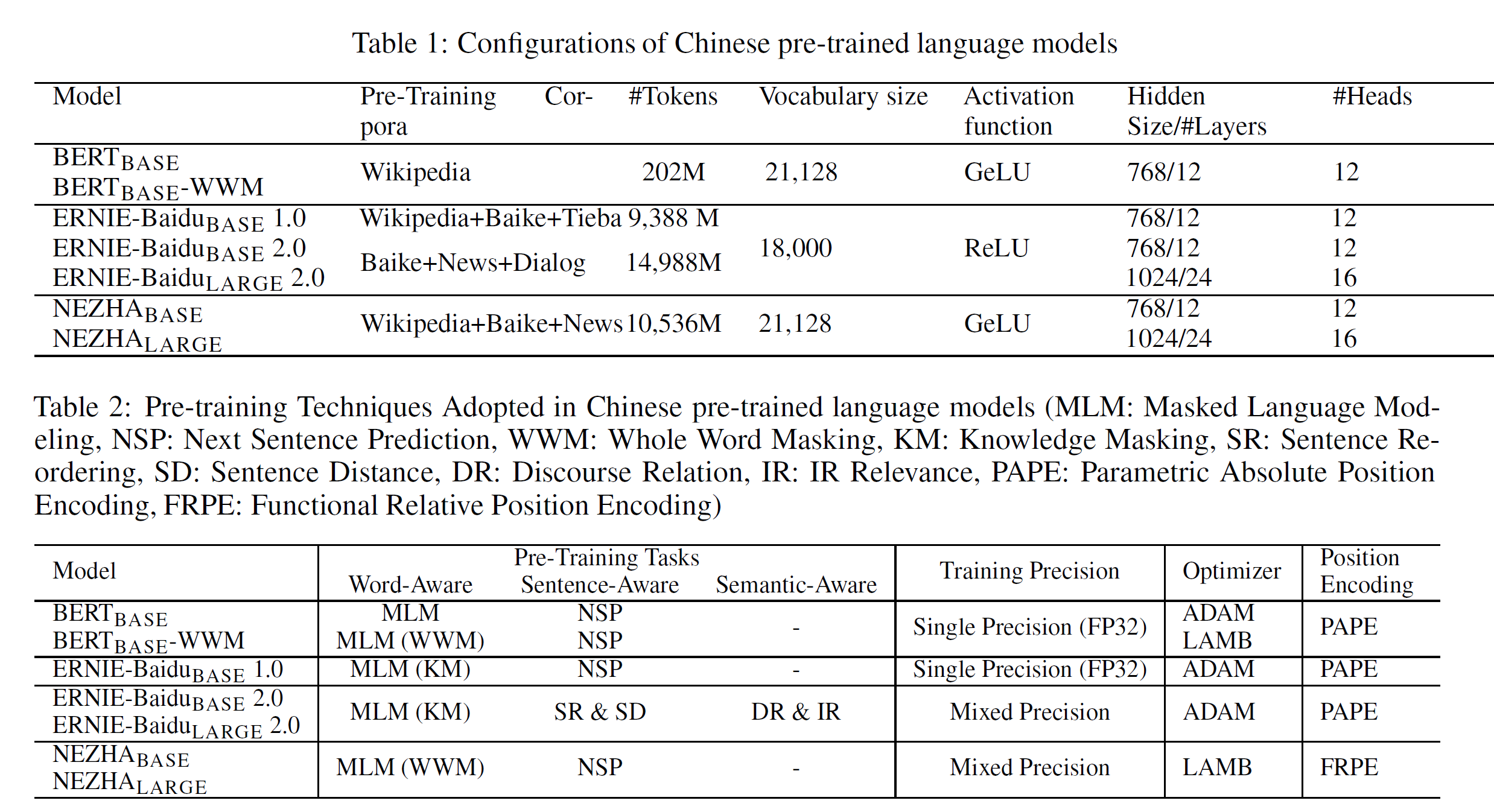
下面2张分别表示:
- 预训练的语料和模型配置情况
- 预训练任务、训练精度、优化器选择、位置编码
实验结果
主要在以下任务上微调:

实验结果:有所提升,但大部分任务干不过ERNIE。
 wechat
wechat alipay
alipay