24. ALBERT 论文笔记
24. ALBERT 论文笔记
本文是ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS 论文笔记。
来自于:
- Google Research
- Toyota Technological Institute at Chicago
摘要
当预训练语言模型表征时提升模型size通常会提升在下游任务的性能。然而,模型越大,GPU、TPU显存消耗越大,训练时间越长。为了处理这些问题,本文使用了两项参数减少技术。还使用自监督loss,聚焦于建模句子内的连贯性,用多句子输入展示了其对下游任务有帮助。
Introduction
两项参数减少技术:
- Factorized embedding parameterization 分解嵌入参数:将原本的大的词汇embedding 矩阵分解为两个小的。
- Cross-layer parameter sharing 跨层参数共享:防止参数随网络深度增加而增长
为了提升表现:
使用SOP——sentence-order prediction,而不是NSP。

3. ALBERT 元素
Factorized embedding parameterization.: 在BERT类的模型中,词向量维度E=隐藏层维度。像BERT-large、xlarge中E也随H增大。从模型角度来说,WordPiece embedding意味中学习context-independent representations上下文无关表示,就是E代表着上下文无关信息。而隐藏层embedding学习的是 context-dependent representations上下文相关表示,就是H代表着上下文相关信息。预训练的目标是学习上下文相关的表示H。Factorized,就是在词表V和隐层H间插入一个低维度的E,具体变换为:
这样参数从以前的减少到了.如果H远远大于E的话,比如H=1024, E=128,V=30,000.减小的参数量还是很大的。但最重要减少参数的在下一项技术Cross-layer parameter sharing。

这里ALBERT-large参数为18M,参数共享。但是下表3中ALBERT-base共享与不共享参数:
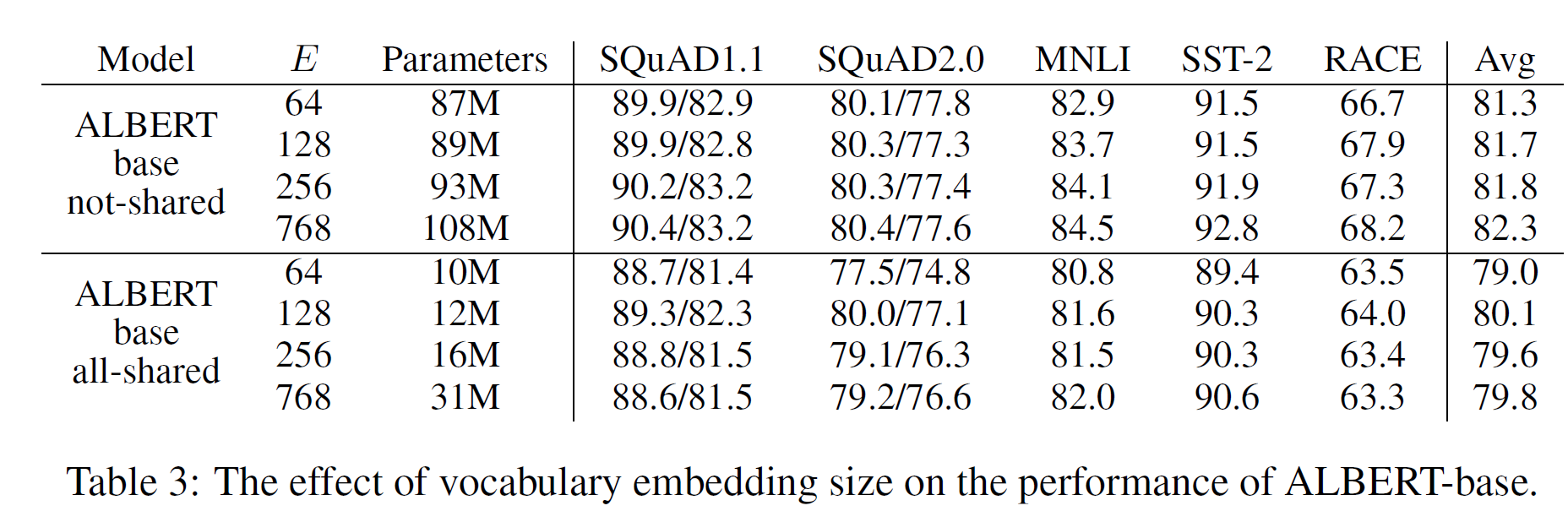
不共享参数,E从768到64参数量从108M到87M,只减少21M参数量。
共享参数,E=64的ALBERT-base参数量为10M。
具体到表1中,BERT-large这部分参数量为(30000+512)x1024=31,244,288。
ALBERT-large参数量为(30000+512)x128 + 128x1024=4,036,608,。那么Factorized embedding parameterization带来的参数减少大约是 31,244,288-4,036,608=27,207,680.大约为27M。那么只能将参数从BERT实际参数量334M-27M=307M左右。不能达到18M。因此减少的原因主要来自于参数共享。
注:这部分计算来自于 小莲子在知乎回答:如何看待瘦身成功版BERT——ALBERT?
Cross-layer parameter sharing.
在参数共享部分,有3中共享模式:只共享attention,只共享FFN,共享所有参数
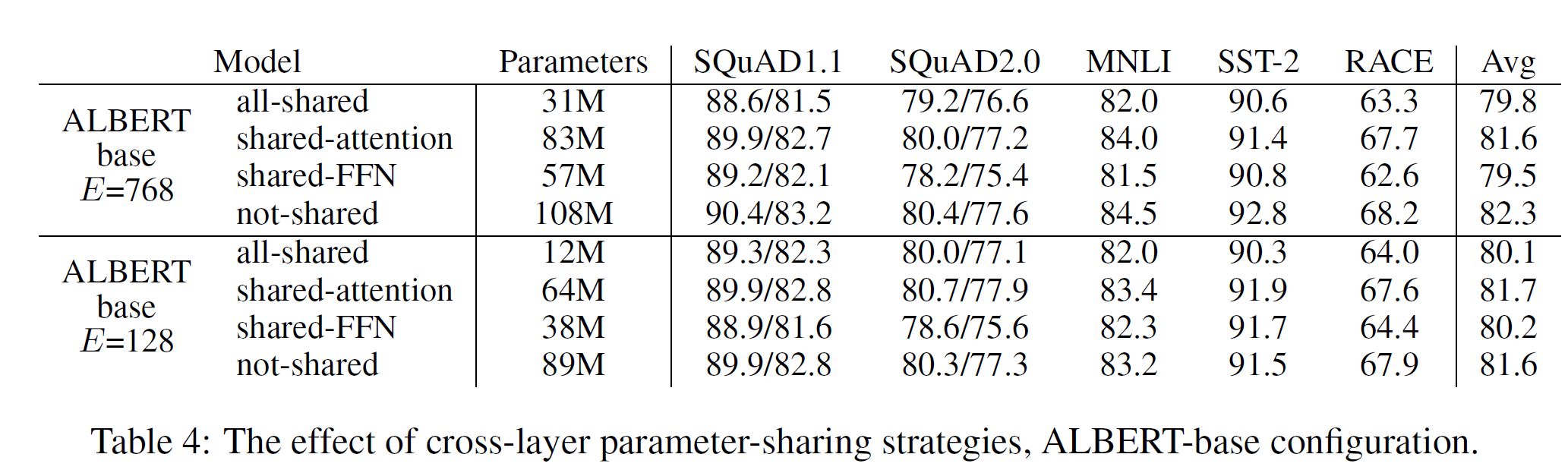
这里要注意的是:只共享attention,性能掉的不太多,但是参数量也不会将太大,感觉都在20%左右。要达到上面那种334M到18M的减少,逐步进行了共享FFN,所有共享尝试。
SENTENCE ORDER PREDICTION(SOP):
SOP正样本是原始同一文档中采样的两个连续句子。
如: 我大四课程都完成了。接下来,我就是毕业生。这两句话作为正样本。
直接交换这两个句子变成:接下来,我就是毕业生。我大四课程都完成了。作为负样本。
然后,如果输入正样本预测为1,输入负样本预测为0.跟NSP任务实现类似。
Inference
 wechat
wechat alipay
alipay