17.Transformer-XL论文笔记
17.Transformer-XL论文笔记
本文是Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context笔记,是后续XLM-RoBERTa的基础。

Abstract
Transformers拥有学习长距离依赖的潜力,但其在语言模型中被固定长度的上下文限制。本文提出了一个新颖的神经架构Transformer-XL(extra long),用其破坏时序连贯性(disrupting temporal coherence)从而能学习超出固定长度的依赖。它由segment-level循环机制和与众不同的位置编码方案组成。该方法不仅能捕获长距离依赖信息,还能解决上下文碎片化(context fragmentation problem) [就是将一段文本分割后,后一段词相对前一段词的语义关系损失掉了]。结果上, Transformer-XL学习的依赖比RNNs长80%, 比vanilla Transformers 长450%, 在长短序列上都取得更好表现,并且在评估时比vanilla Transformers快1800+倍。开源代码地址: transformer-xl 官方.
1. Introduction
一方面,像RNNS的各种变种都在解决长距离依赖问题,RNNs本身由于梯度消失和爆炸难以优化。梯度裁剪这种技巧也不能有效解决这个问题。经验上,LSTM语言模型上下文长度最好在200左右,就没有什么进一步提升空间了。
另一方面,在注意力机制中,直接连接长距离的单词对来固定特征,能缓解优化并学习长距离信息。vanilla Transformers中设计了一系列辅助损失来训练针对character-level语言模型的深层Transformer网络。尽管其成功了,但其还是在分割的固定长度的几百个字符(characters)片段上,信息没有跨越片段。这样模型就不能捕获超过预定义上下文长度的信息。另外,固定长度片段通过选择连续的字符块来创建而不考虑句子或其他任何语义边界。因此,模型缺乏必要的上下文信息,来预测开始几个词,导致低效地优化和推断性能不佳。本文将该问题描述为上下文碎片化(context fragmentation).
为了处理上述问题,提出了Transformer-XL(extra long).不再像vanilla Transformers 一样从零开始计算新片段的隐藏状态。而是将前一个片段的隐藏状态缓存下来,跟下一个片段建立循环连接给其使用。这样,建模非常长的依赖关系也是可能的,因为信息能够通过循环连接传播。同时,前一个片段传递的信息也能解决上下文碎片化问题。
更重要的是,Transformer-XL使用相对位置而不是绝对文章,为了能让缓存的隐藏状态再利用不造成时序冲突。(下面会详细讲).因此,作为一项额外的技术贡献,引入简单但有效的相对位置编码公式,能推广使用使得注意力在评估阶段比训练阶段要更长。
3. Model
3.1 Vanilla Transformer Language Models
为了应用Transformer 或 自注意力到语言模型,关键问题是如何训练一个Transformer来有效地编码任意长度的上下文到固定长度的表示。给定有限的内存和计算能力,一个简单的方案是将余下的上下文序列用一个非条件的Transformer decoder,类似于前馈神经网络。然而,这通常在实践中有限的资源是不可行的。
一个可行方案是直接把余下的语料分割成短的可处理片段,只在每个片段上训练模型,忽略当前文本中使用单词和之前片段单词之间的信息。这就是vanilla Transformers提出来的想法,这里称作vanilla model。如下图1所示。

在该训练流程中,信息无论是前向还是后向都不会跨片段流过。这在使用固定长度上下文时有两个严重限制.
- 最大长距离依赖上限在片段长度,也就几百个字符长度。
- 尽管自注意力机制不像RNNS那样受梯度消失影响,vanilla model还不能完全利用该优化的优点。(训练了前面片段的隐藏状态,却无法被后面的片段利用与后面片段相关的注意力)
- 尽管其可能使用padding到相关句子或其它语义边界。实际上还是简单分割长上下文到固定长度的片段。这又导致上下文破裂问题。
在评估阶段,在每一步,vanilla model也输入跟片段一样长的上下文,但仅仅在最后一个位置预测一个。然后,就一步一步网右移。如图1b.这样保证,每个预测利用训练中看到的最大长度,并减轻训练阶段遇到的上下文破裂问题。但是评估阶段代价非常高。(它预测时,每预测下一个词,都要重构一遍上下文, 并从头开始计算,计算速度非常慢。)
3.2 Segment-Level Recurrence with State Reuse
注: Transformer-XL不能将语料混洗,要按照顺序,在一个batch中一次输入。不然前一个片段和后一个片段的上下文关系就没了。
为了解决使用固定长度上下文问题,作者引入循环机制到Transformer架构中。在训练时,之前片段计算的隐藏状态序列是固定住并缓存下来,在处理新的片段是再利用,像下图2a中一样。(图中新的片段拿循环连接将前面片段的固定隐藏状态连接起来,这样就能传递信息流了,也就能利用前面片段的历史信息。)
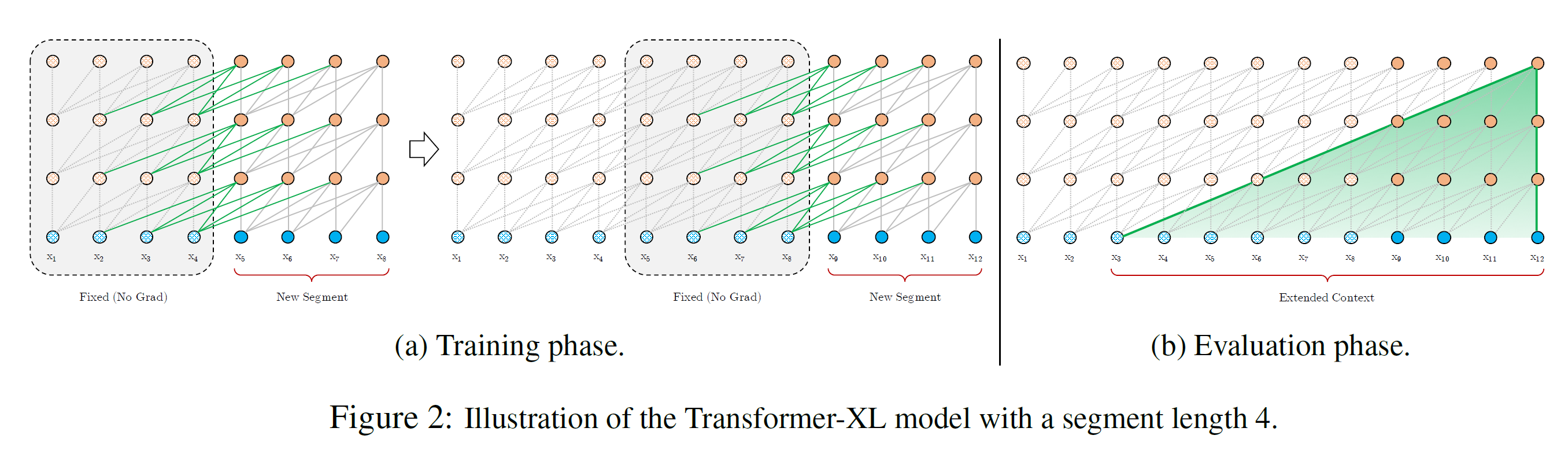
尽管梯度仍然停留在一个片段内,但额外的输入允许网络利用历史信息,这导致模型有长距离依赖的能力避免上下文碎片化。正式定义,假设有两个长度为L的片段:
第个片段对应生成的第层的隐藏状态序列表示为.
- 表示隐藏状态维度,是片段长度。
那么,第片段的第层隐藏状态按照以下方式生成:
将固定并缓存下来的,论文叫stop-gradient,记作.
这里表示:将和按位置拼起来。就是相邻片段对应的隐藏状态拼接。这样,得到了
接下跟BERT类似得到. 其中依赖前一个片段的隐藏状态,是乘以得到。
最后,过常规Transformer层得到.
总的表示就是论文中,
在评估阶段,像图2b中,如果每个片段是L,训练时划分了N个片段,它能获取的最大上下文信息长度为.(实际上GPU显存限制,设置为m).而且会比Vanilla model快1800+倍,它有缓存好的状态并完整保存下来,评估直接用,不用从头计算。
3.3 Relative Positional Encodings
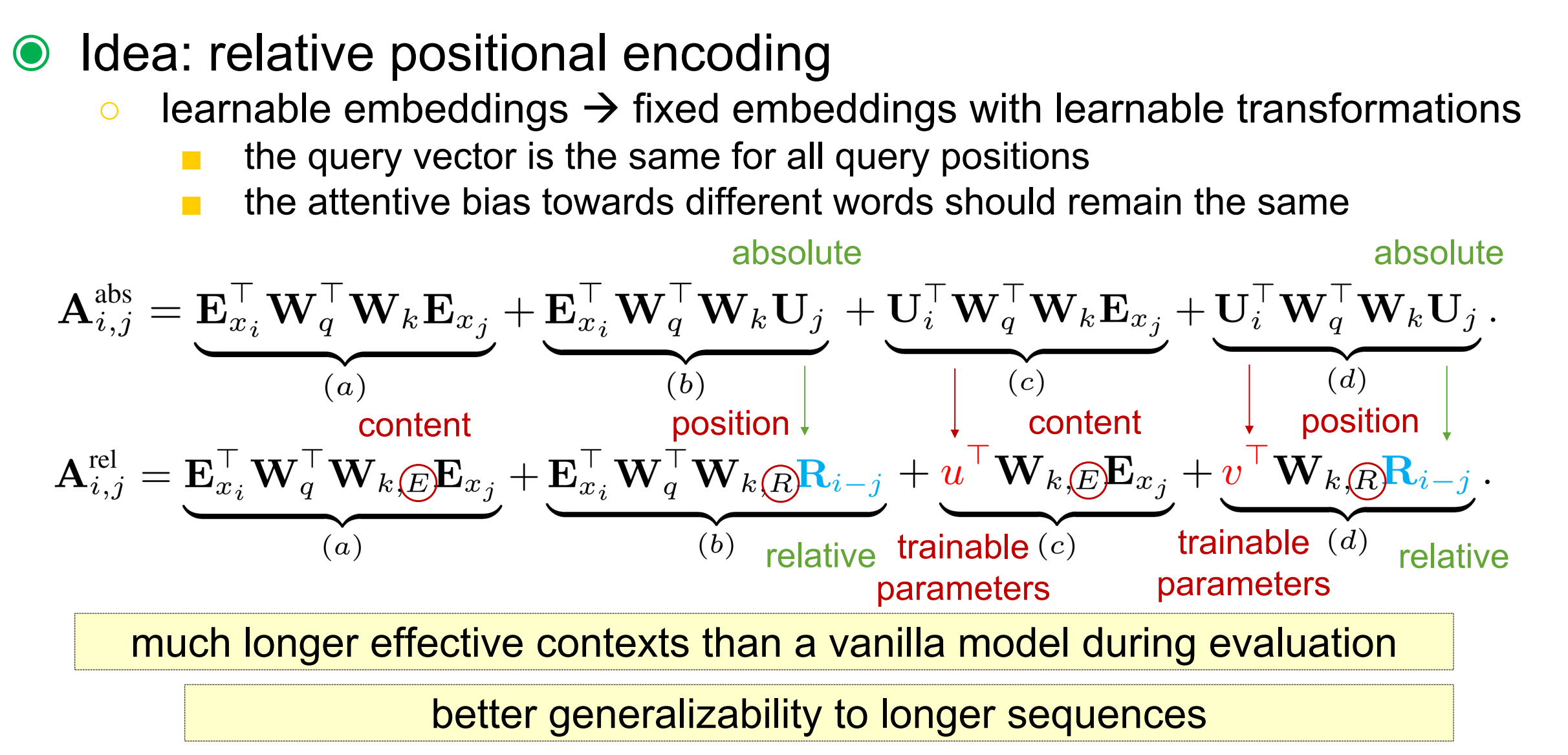
在标准的Transformer中,序列的次序信息用positional encodings表示,记作,其中表示第列,对应片段中第个绝对位置,是模型能输入的最大长度。实际上,就是将word embeddings和positional encodings两者按元素相加。如果按这种方式,可以简单表示为:
其中,
表示序列的词嵌入。
表示Transformer 变换
可以看到,都是和相加。没有区别,其中, 会造成模型损失变得陡峭。
(原因是:像BERT随机生成position embedding然后训练得到,原始Transformer中sin/cos位置编码得到,那么如果训练片段长度为4,其位置编码为[0, 1, 2, 3]。拓展上下文长度为8时位置编码应该为[0, 1, 2, 3, 0, 1, 2, 3]。这是不合理的。引入解决措施:相对位置编码。)
举例来说,query 向量要注意到key向量.就是计算k去查询q时,(理论上要看到i位置之前的所有位置). 不需要知道每个k向量的绝对位置来识别其在片段中的时间次序。相反,只需要知道相对位置。实际上可以创建一系列相对位置的encodings。这里第列表示一个与基准位置的相对距离。为了动态地增加相对距离到注意力分数中,query向量要轻松区分不同距离上的表示。并且不能丢掉时序信息,像绝对位置信息能从相对距离上递归地恢复时序信息。
(公式跟paper一样, 图来源于陈蕴侬教授ADL slide)。
这个部分推荐看4相对位置编码讲解。
- 第一个改变是,将所有绝对位置编码表示为相对位置编码 。这本质上反映了先验只注意跟其相对位置的距离。是不用学习的sin编码矩阵。
- 引入训练参数来替换,上面公式中c项。无论query 位置如何,对不同单词注意力bias应该保持一样。参数来替换,如d项。
- 最后,论文故意分开两个权重矩阵和来对应地生成基于content的key向量和基于location的key向量。
公式中四项理解:
- (a)项表示基于内容的“寻址”attention
- (b)表示捕获的内容相对于每个位置bias
- (c)表示内容全局的偏差
- (d)表示位置全局的偏差
对应绝对位置公式:
第一项刻画了位置i的
token和位置j的token的相关性。第二项刻画了位置i的
token和位置j的position的相关性。第三项刻画了位置i的
position和位置j的token的相关性。第四项刻画了位置i的
position和位置j的position的相关性。 ——引用[4]
Transformer-XL整体计算公式如下:
其中,A需要对全部的(i, j)对计算。
Inference
[1] Transformer-XL解读
[2] Transformer-XL
[4] 三、Transformer XL
 wechat
wechat alipay
alipay