12.2 GPT系列论文: GPT-2 笔记
12.2 GPT系列论文: GPT-2 笔记
本文是 Language Models are Unsupervised Multitask Learners无监督多任务学习语言模型,即GPT-2的论文。这里作为GPT系列论文第二篇。
摘要
自然语言处理任务,如问答,机翻,阅读理解,以及概括,都是在特定任务数据集上典型的监督学习方法。作者展示了在新的百万级网页数据集WebText上训练时,这些语言模型在没有任何明确的监督数据的情况下开始学习这些任务。以文档和问题条件,用该语言模型生成的答案在CoQA数据集上达到55 F1,并且没有使用127,000+训练样本就相当或超过4个基线系统中3个的性能。语言模型至关重要的能力是零样本任务迁移的成功,并且其能在一个流行的对数线性跨任务上提升性能。作者的最大模型,GPT-2,一个15亿参数的Transformer,在零样本设置下8个测试语言模型的数据中7个取得最佳成绩,并且在WebText上仍然前拟合。模型中的样本反映这些提升并包含连贯的文本段落。这些发现表明通往构建语言处理系统的有希望路径是从语言处理系统自然发生的演示中学习执行如何执行任务
1. 介绍
机器学习系统现在擅长(在预期上)==用大规模数据集、高容量的模型和监督学习的组合==来训练它们的任务。然而这些系统是脆弱的并且对在数据分布和特定任务有轻微改变敏感。当前系统被更好地描绘成狭隘的专家而不是称职的全才。作者想朝着能执行许多任务的通用系统——最终不需要为每个任务手工创建和标注训练数据集。
创建ML系统的占支配地位的方法是收集在目标任务上显示正确行为的训练样本,训练一个系统来模仿这些行为,然后在独立同分布的留出样本上进行试。这有助于在狭隘的专家任务上取得了成功。但在字幕模型、阅读理解系统和图像分类器上,输入的可能多样性会造成不稳定性就凸显了该方法的缺点。
作者怀疑单一领域数据集上训练单一任务导致是导致在当前系统中模型泛化能力不足。让当前架构朝着强壮系统前进似乎需要在广泛领域和任务上训练和测试性能。最近几个基准已经提出了,如GLUE和decaNLP就开始研究这个。
多任务学习对于提升通用性能是一个有希望的框架。然而,在NLP里多任务仍是一个萌芽阶段。近期工作报告了不太大的性能提升,迄今为止两项最有希望的努力分别训练了总共10和17对(数据集, 目标)。从元学习角度来看,每个(数据集, 目标)对是送数据集和目标分布中采样单一训练样本。近期ML系统需要成百上千的样本来催生泛化好的函数。这表明多任务很多需要许多有效的训练样本对来实现跟当前方法一样的获得成功的迹象。继续扩大数据集的创建是非常困难的,并且用当前方法蛮力实现目标设计到可能需要的程度是不行的。这就需要对于多任务学习探索额外的设置。
当前在语言任务上的最好的实现是利用一组预训练和监督学习微调。该方法历史悠久,趋向于更灵活的迁移形式。首先,是学到的词向量被用作特定任务架构的输入。然后,是RNN的上下文表示转换。近期工作表明特定任务架构不再需要,而许多自注意力块转换使有效的。

这些方法仍然需要监督训练以便任务使用。当只有最小的或无监督数据可行时,另一项工作已经证明语言模型有希望执行特定任务,如常识推理和情感分析。
在本文中,联系两个方向的工作,并继续趋向更通用的迁移学习方法。作者证明==语言模型能在零样本设置上执行下游任务——不需要任何或架构修改==。还证明了该方法的潜力,突出语言模型在零样本设置下执行一系列广泛任务的能力。作者依赖这些任务取得了有希望的,竞争的和最佳结果。
2 方法
语言模型的核心方法就是Bengio 2003年[neural probabilistic language model]提出的:
该方法允许对以及形式的条件概率进行采样和估计。在近些年,这已经在模型表达上已经有很大的改进,可以计算这些条件概率,如自注意架构Transformer。
学习做单一任务的模型能表达为以估计条件分布作为概率分布的框架。因为通用系统能做许多任务,甚至同样输入,它不仅仅基于输入也基于执行的任务来产生输出。这样模型就应该是. 这在多任务和元学习中以各种形式设置。条件任务提出在一个架构级别实现,如具体任务的编码器和解码器或者算法级别如MAML的内外循环优化框架。但是如McCann 2018[Multitask learning as question answering]例证, 语言给特定任务提供了可行的方式,输入,和输出一起作为一个符号序列。例如,翻译训练样本能写作一个序列(翻译成法文, 英文文本, 法文文本)。同样地,阅读理解训练样本能写作 (问题的答案,文档,问题,答案)。McCann 证明这可以训练单一模型,如MQAN,来用这种形式的序列在样本上推断和做许多不同任务。
在原理上,语言模型也能够学习McCann等人 2018[Multitask learning as question answering]提到的任务,而无需明确监督哪些符号是要预测输出的。因为监督学习目标跟无监督学习目标是一致,但只在序列的一个子集上评估,无监督学习目标的全局最小也是监督学习目标的全局最小。在稍微玩具性质的设置中,Sutskerver 等人,2015[Towards principled unsupervised learning]讨论的有关密度估计作为准则的训练目标被忽略了。这个问题反而变成了作者是否能够在实践中中优化无监督学习目标来收敛。初步实现确认足够大的语言模型能够在玩具式的设置下执行多任务学习,但学习要比明确的监督学习方法慢。
尽管上面描述的给“野性语言”的混乱进行精心设计设置是一个大的进步。Weston (2016)认为,在对话背景下,需要开发一个系统能够从自然语言中直接学习并证明一个概念——学习一个QA任务,用一个“teacher”输出的前向预测不需要奖励信号。(不需要监督学习)。虽然对话是一种有吸引力的方法,但作者担心其过于严格。互联网包括不需要互动交流的大量被动可用的信息。作者推测有足够容量的语言模型将开始学习推断和执行在语言序列中证明中展示的任务以便更好预测它们,无论其获取方法是什么。如果一个语言模型能够做到这点或者将来能,它实际上将做无监督学习。作者通过分析语言模型在各种任务的零样本设置中的性能来测试是这样的。
2.1 数据集
以前用单一领域的文本,进一步用网络抓取的多样的海量文本Common Crawl.
本文用作者创建手工抓取过滤来自Reddit 3 karma以上生成的数据集==WebText==,截止于12.2017,800万文档总共40GB数据。但其是其它数据集的常见数据源可能会造成测试数据和训练数据重叠。(因为这个, WebText 移除了涉及Wikipedia的文章)
自然语言中英法翻译在WebText训练数据集出现示例如下表1:

2.2 输入实现
通用语言模型应该能计算捕获任何字符的概率。在10亿词基准上,byte-level LMs比word-level效果要差,本文发现也一样。
Byte Pair Encoding Sennrch等人 2915 是一种介于字符级别和单词级别中间的实用语言模型,其对于高频符号序列字符级别输入和对于低频符号序列字符级别输入能有效地插值。尽管它的名字有byte的,但有关BPE的实现通常是在Unicode字符编码上操作而不是Byte。该实现需要包括整个Unicode符号以便给所有Unicode字符建模。这将导致没有添加组合符号的字符之前基础词汇表就超过130,000。这与 BPE 经常使用的32,000到64,000字符词汇表是令人却步的大。相比之下,字节级别版本的BPE只需要大小256基础词汇表。然而,由于BPE使用基于启发的贪婪的频率来构建字符词汇表,将直接导致应用字节序列的BPE会造成次优合并。作者观察BPE包含许多版本的常用词如dog, 因为其经常出现许多变种如 dog.dog!dog?.这导致就是有限的词汇表槽位和模型容量的次优化分配。为了避免这种情况,作者阻止BPE为任何字节序列跨字符类别合并。作者只例外为空格添加,这显著地提升了压缩效率,同时在跨多个词汇字符中添加最少的单词碎片。
这种输入表示允许作者将单词级别的语言模型的经验优势和字节级别方法的通用性结合起来。因此作者的方法可以给任何Unicode字符分配概率,这允许作者在不管是预处理,字符化或词汇大小的任何数据集上评估作者的模型。
2.3 模型
模型使用还是Transformer,在GPT-1 上小修改。
- Layer Normalization 移到每个子块的输入,类似于预激活的残差网络
- 最后一个自注意模块后加一个Layer Normalization
- 用初始化残差层权重,N是残差层数目
- 词汇表扩大到1024
- 上下文从512增加到1024
- batchsize 增加到512
3. 实验
训练和基准化了4个参数大小近似对数均分分布语言模型。如下表2.
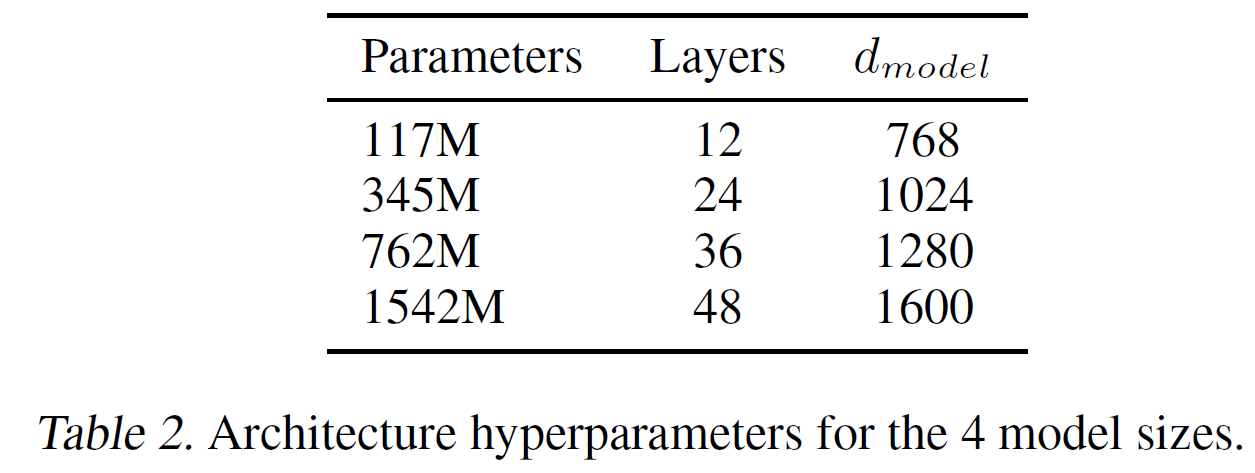
- 最小的近似等于原始的模型
- 第二小的等于最大的BERT
- 最大模型叫GPT-2
- 每个模型的学习率都在5%的留出WebText数据集上手工调到最好的困惑度
- 所有模型在WebText上都是欠拟合的并且留出数据集上困惑度训练更长时间还有提升。
3.1 语言模型
作为零样本任务迁移的第一步,作者有兴趣了解 WebText LM 如何在零样本领域迁移中执行他们训练的最基本任务——语言建模。因为作者的模型在字节级别上操作并且不需要有损失的预处理或tokenization。作者能在任何语言模型上基准评估。在语言模型数据集上的结果通常用一个数值来报告,其被以平均负对数概率的放缩或者去幂的形式计算预测类别单元——通常是字符、直接或者单词。作者估计一样的值是通过计算一个数据集对于WebText 语言模型的对数概率并除以类别单元的数目。对于这些数据集中的许多数据集,WebText 语言模型将在分布之外进行某种意义的测试,必须预测积极标准化的文本,tokenization 组件字符如断开的标点符号,乱序的句子,甚至是
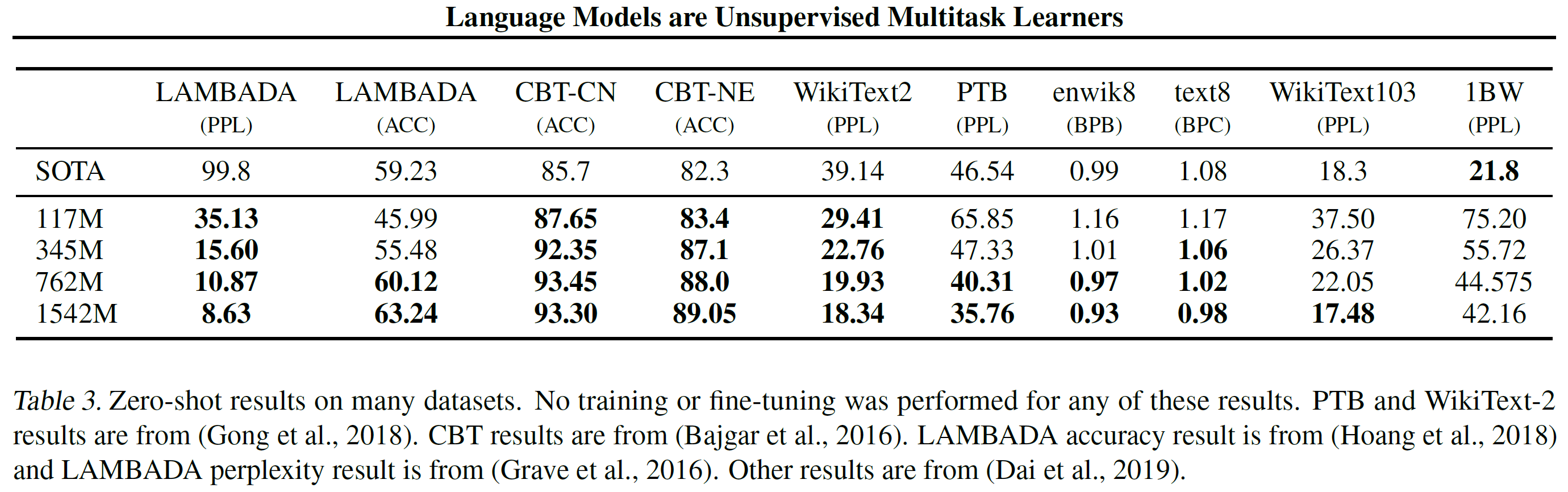
WebText语言模型跨领域和数据集迁移良好,在零样本设置下,8个数据集中7个提升到了最佳成绩。在小数据集上,如Penn TreeBank和只有1到2百万训练字符的WikiText-2也注意到有大的提升。长依赖测试数据集LAMBADA和儿童书籍测试,都有大的提升。但在10亿单词基准测试中表现比之前工作提出的模型差。这可能使其结合了大数据集和一些破坏结构的预处理——10亿单词基准测试移除了所有长范围结构导致句子级别是打乱的。
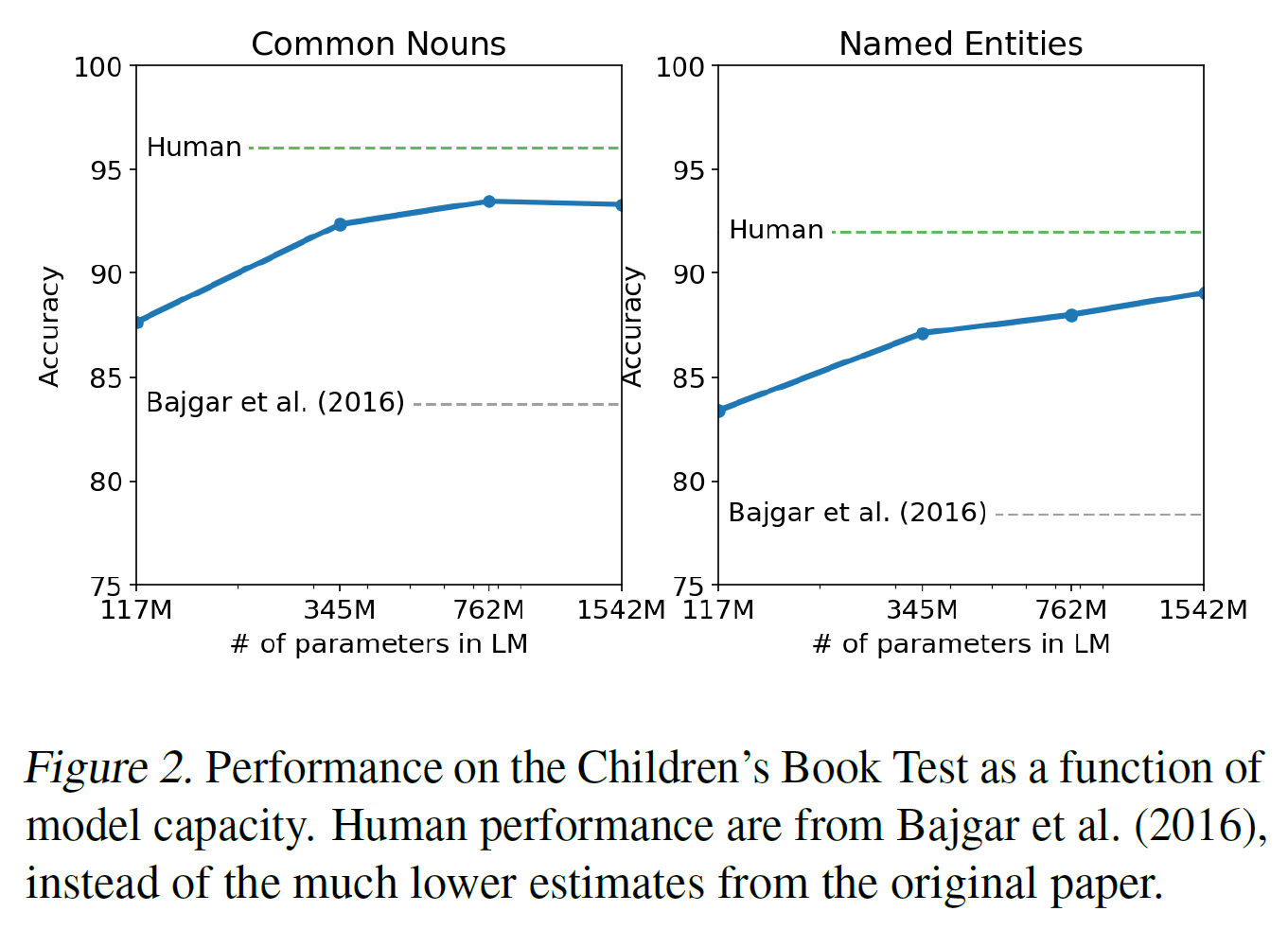
3.2 儿童书籍测试
儿童书籍测试是创建用来检查语言模型在不同类别词上的表现,如命名实体,名词,动词以及介词。报告不采用困惑度,而使用预测对删除单词的10个选择的完型填空测试。遵循在原论文中引入的语言模型方法,根据这个语言模型计算这个选择在每个选择的概率和剩下句子条件的概率,预测最高概率作为预测结果。如表2所示,在测试集上,模型表现随着模型大小稳定提升,跟人类表现的差距在缩小。数据重叠分析如一本在CBT测试集中的书,Rudyard Kipling的《奇幻森林》,也在WebText里,但作者在验证集上报告结果没有显示显著的重叠。GPT-2在普通名词上取得了93.3%的最佳结果,在命名实体上也取得了89.1%。应用去分词器从 CBT 中删除 PTB 样式标记化组件。
3.3 LAMBADA
LAMBADA数据集测试系统在文本中的对长距离依赖关系建模的能力。GPT-2提升了成绩,其造成CPT-2预测错误的原因主要是没有有效的终止符。
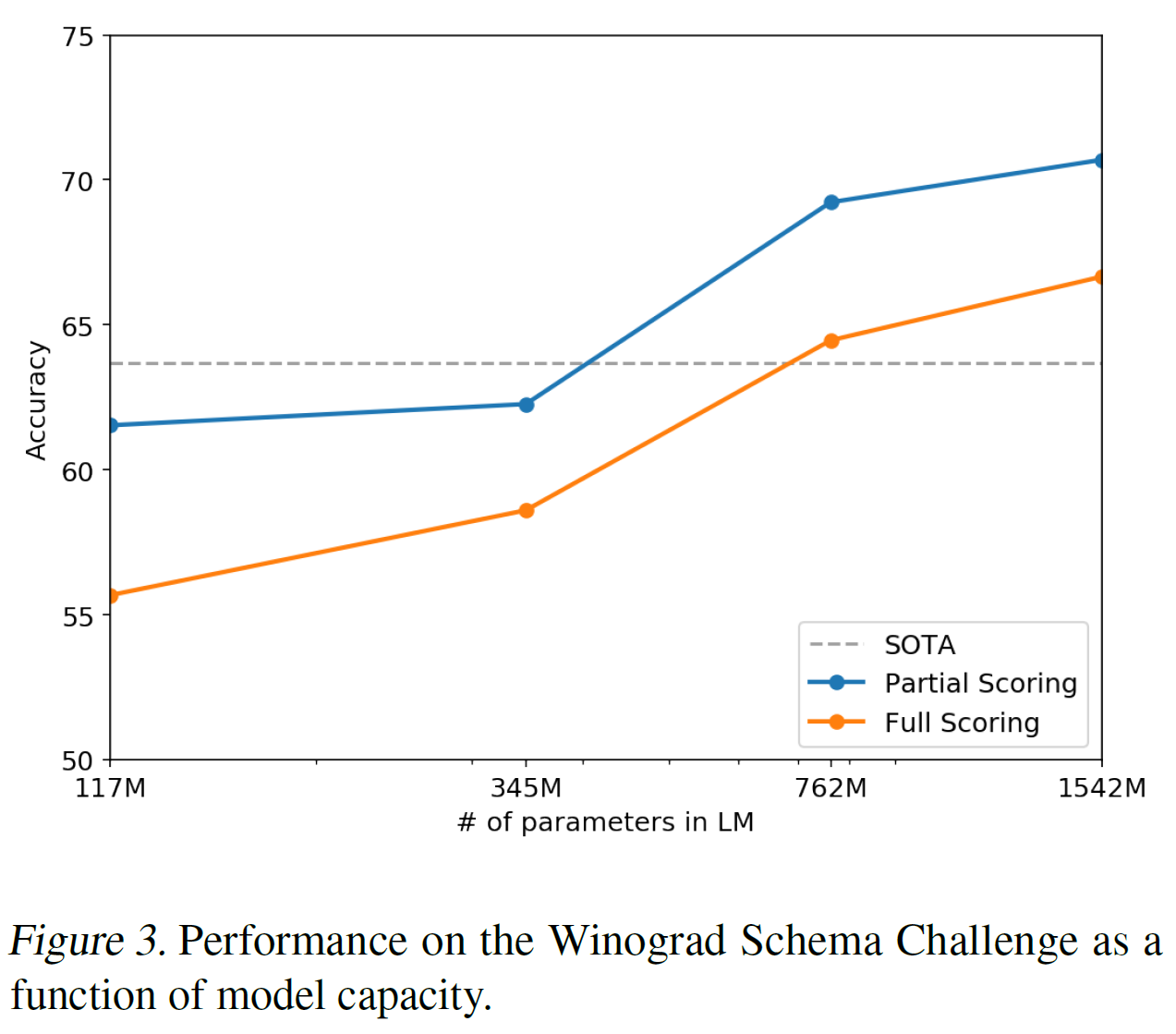
3.4 威诺格拉德模式挑战
威诺格拉德模式挑战被构建用来衡量一个系统做常识推理的能力,即测试解决文本歧义的能力。近期Trinh&Le (2018)证明了语言模型在该挑战的巨大成功,就是语言模型用高概率来预测歧义的解决方案。作者遵循他们的问题计算公式,并用全部和部分分数技术可视化作者模型表现如下表3.GPT-2 比当前最佳准确率的提升了7%,达到70.70%。数据集非常小只有273个样本,所以作者建议阅读Trichelair 等人(2018)来帮助将该结果置于问题背景来理解。
3.5 阅读理解
CoQA是由7个不同领域的自然语言对话对构成的文档。在一个文档条件下,在验证集上,从GPT-2中贪婪解码得到历史相关的对话和最终的字符A取得55的F1。BERT监督学习取得89F1,但GPT-2的表现毕竟是无监督学习还是可以滴。
3.6 摘要
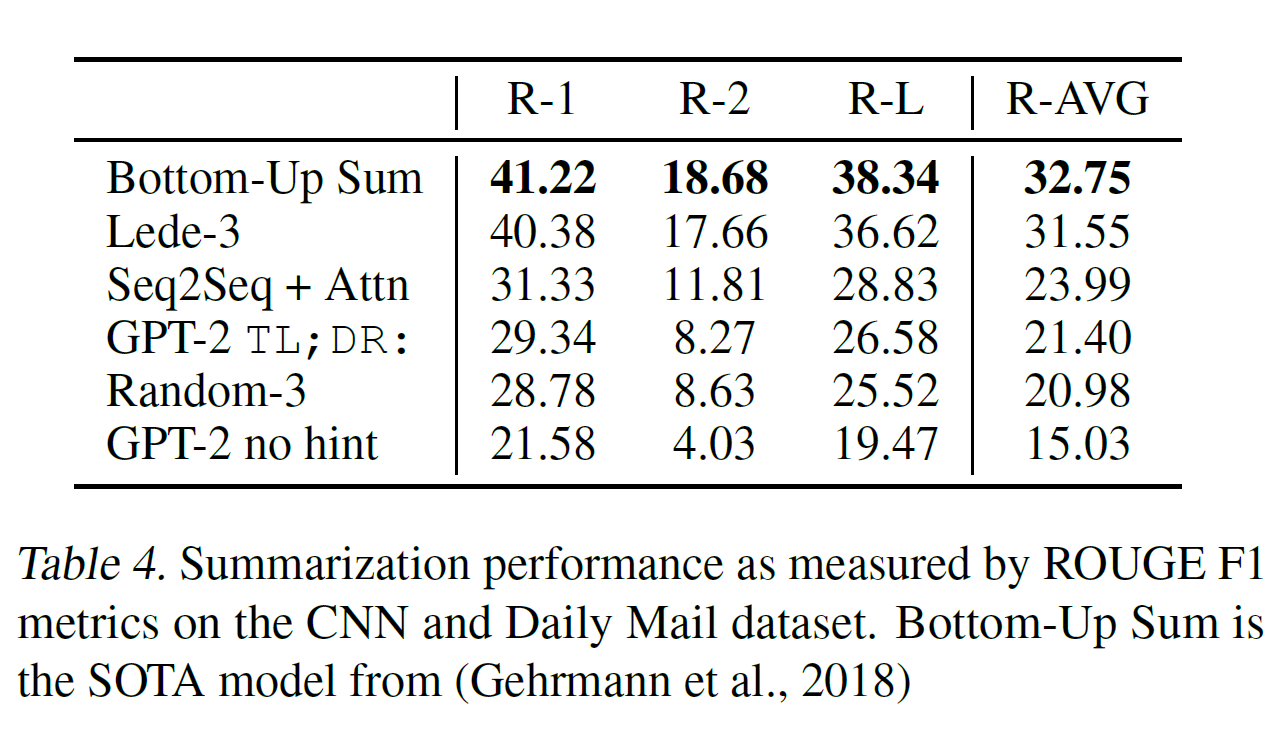
在CNN和每日邮报数据集上测试摘要的能力。为了引导摘要行为,作者在文章后面添加文本TL;DR:并用k=2的Top-k的随机采样(Fan 等人 2018)生成100个字符,这减少了重复并鼓励更抽象的摘要而不是贪婪解码。作者使用在100个token中生成的最先的3个句子作为摘要。会聚焦于最近的文章或者不清楚具体细节,如下表4。
3.7 翻译
作者测试GPT-2是否开始学习如何翻译一种语言到另一种语言。为了帮助推断这是期望的任务,作者在格式如english sentence=french sentence的样本对的上下文中调节语言模型,然后在english sentence=最终提示之后,作者从模型中用贪婪解码并用第一个生成的句子作为翻译。GPT-2在WMT-14 英语-法语上取得5 BLEU,都不是太好的成绩。
3.8 问答
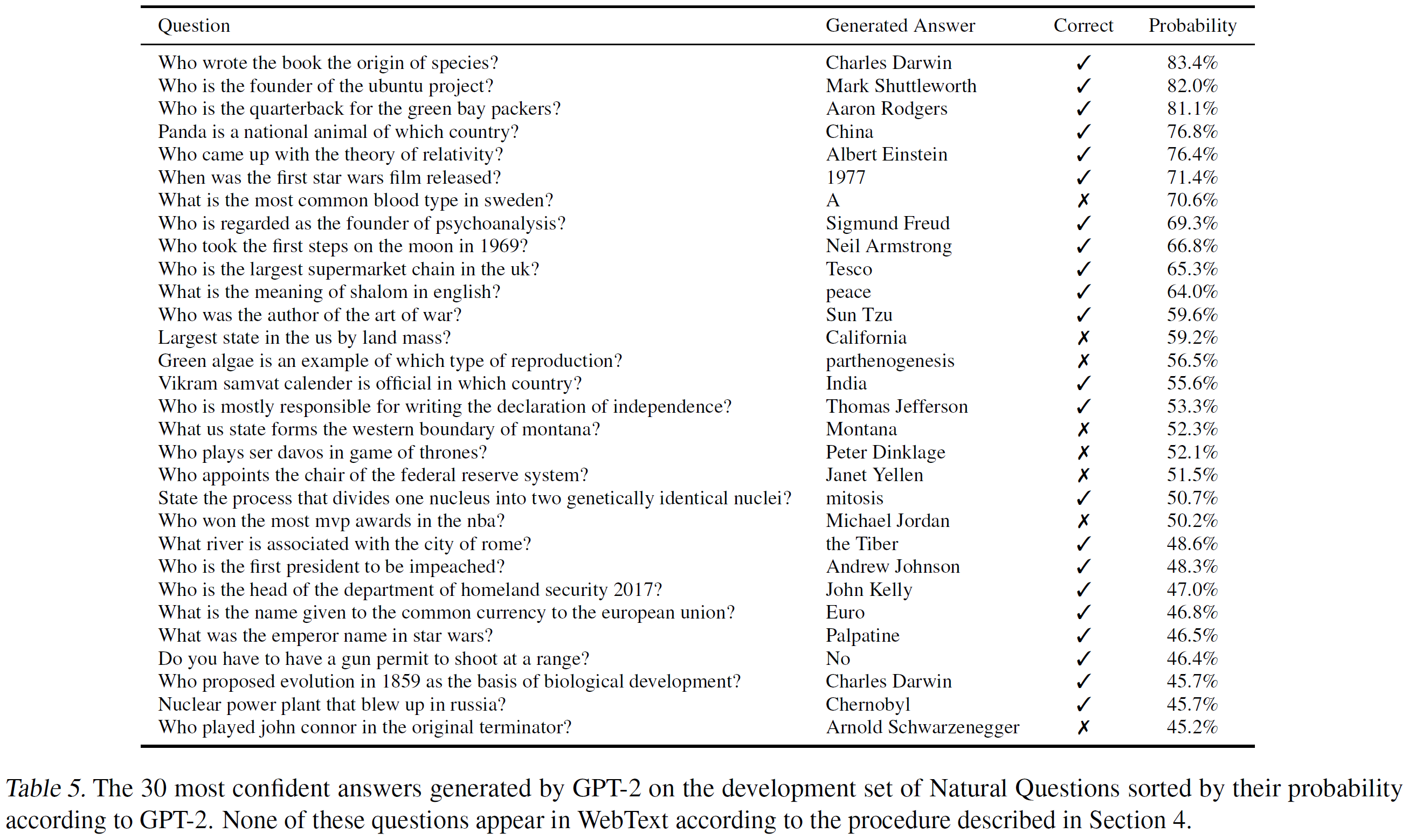
30个GPT-2生成的答案如下表5,其表现还是远远弱于30到50%的用文档提取问答的杂交的信息检索的开放领域的问答系统,
4. 泛化与记忆
数据集越来越大可能会有数据重叠的现象,所以首先就是分析训练数据和测试数据有多少重合。
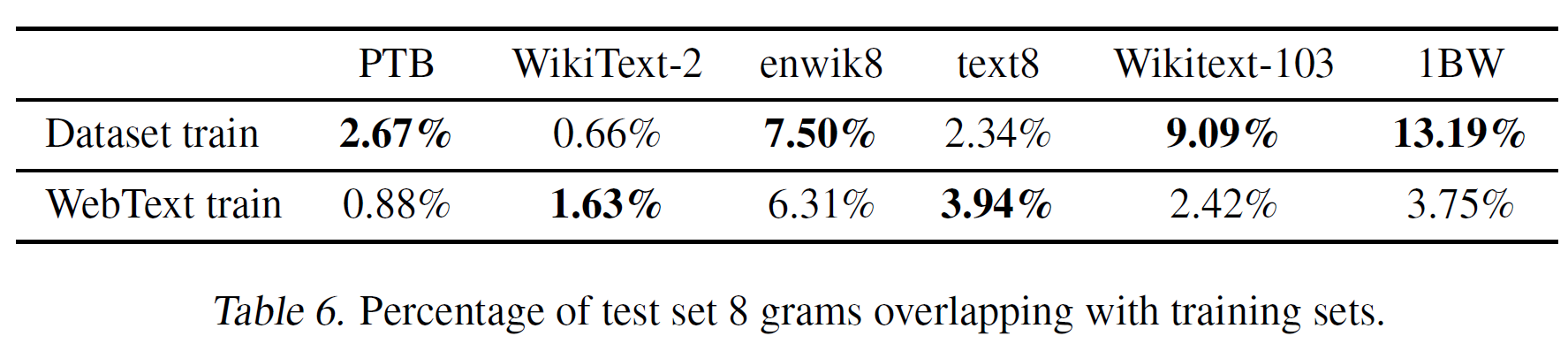
用包含WebText的8-grams的训练数据集字符创建Bloom filter,假阳性率上界只有.用1M字符串进一步验证假阳性率的下界为0.
布隆过滤器让作者计算,给定数据集,8-grams来自该数据集也来自WebText训练数据的百分比。具体如下表6所示。
本文又分析了在WikiText-103测试集,威诺格拉德模式挑战等数据集的重叠情况。
总的来说,WebText数据集的训练数据和特定任务的验证集有重复情况,对结果影响不大。大部分数据集没有发现大量重复的情况,具体如上表6所示。
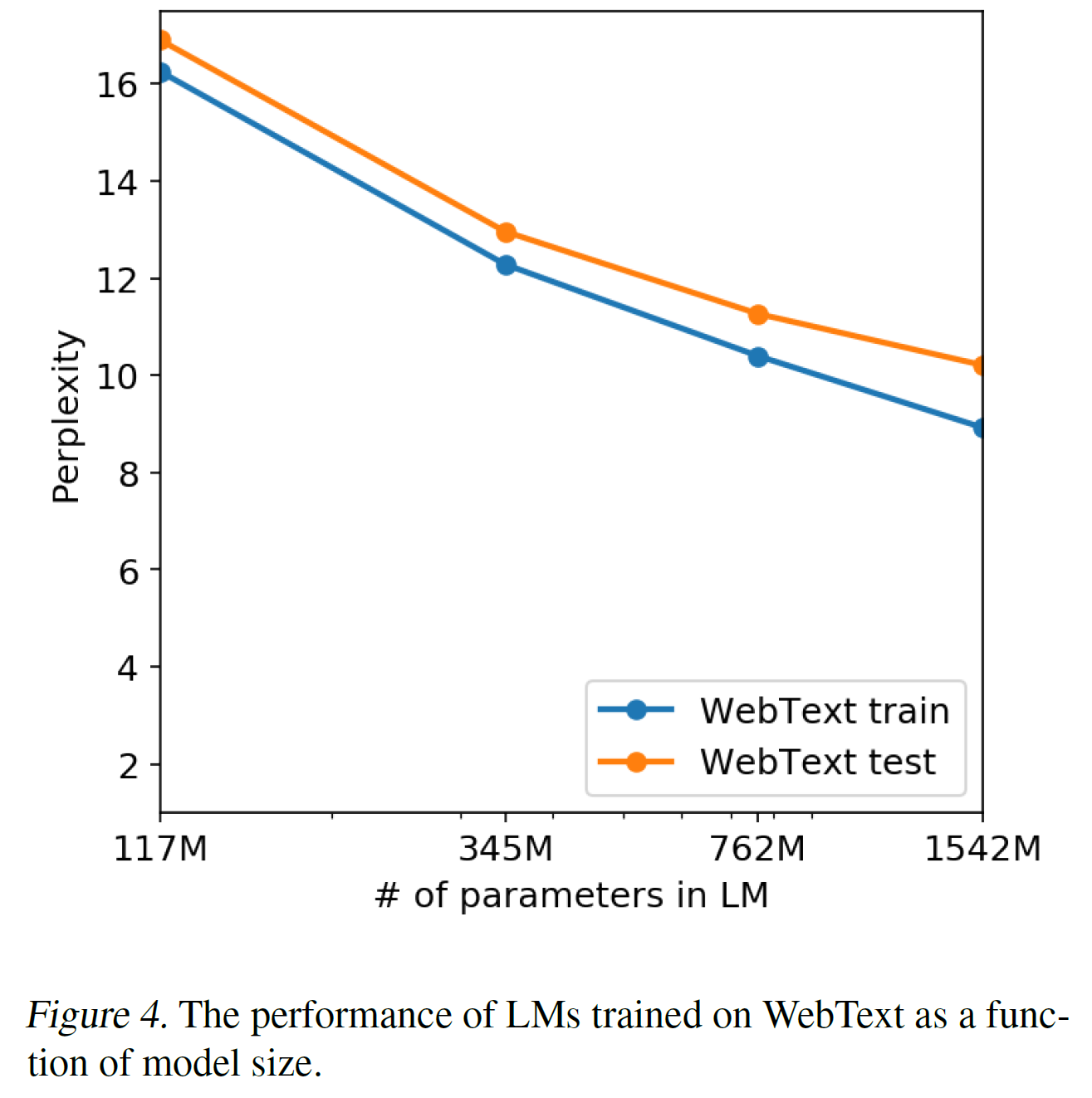
另一种确定性的潜在方法关于WebText语言模型是否归功于其记忆,就是检查它们在留出集上的表现,如下表4,性能在WebText的训练集和测试集都类似并且都随着模型大小增加而上升。这表明GPT-2在许多方向仍然欠拟合。
GPT-2也能写有关发现谈论独角兽的新闻文章。例子如下表13.

后面部分就是一些工作介绍,就不翻译了,只有GPT-2的改进就是2.3小节部分,还有其优势在摘要和各个数据集上的表现都有,这里就不写一遍了。
 wechat
wechat alipay
alipay

