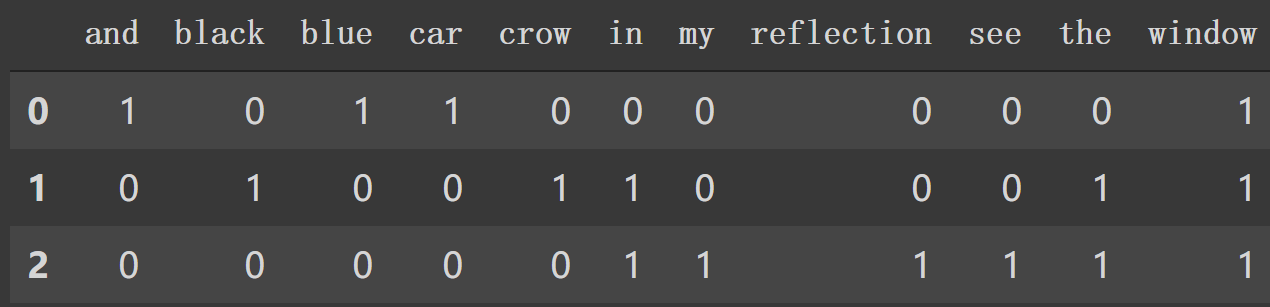
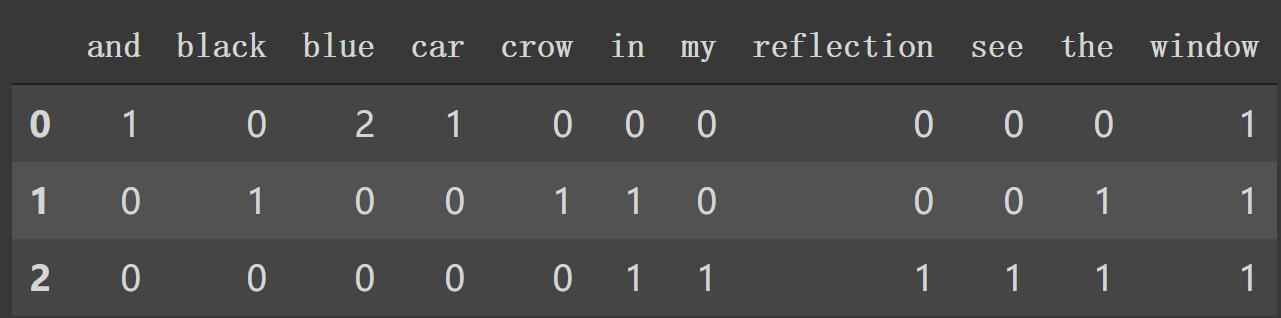
texts = [ "blue car and blue window", "black crow in the window", "i see my reflection in the window" ]
先建立词汇表:
1 2 3 4
vocab = sorted(set(word for sentence in texts for word in sentence.split())) print(len(vocab), vocab) ================================================================================== 12 ['and', 'black', 'blue', 'car', 'crow', 'i', 'in', 'my', 'reflection', 'see', 'the', 'window']
按词汇出现位置来向量化输入文本。
1 2 3 4 5 6 7 8 9 10 11 12 13
import numpy as np
defbinary_transform(text): output = np.zeros(len(vocab)) words = set(text.split()) #如果每个词在词汇表中就把该位置置为1 for i, v inenumerate(vocab): output[i] = v in words return output
import pandas as pd import numpy as np from sklearn.cluster import MiniBatchKMeans from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.decomposition import PCA import matplotlib.pyplot as plt from sklearn.datasets import load_files
defonly_nouns(texts): output = [] for doc in nlp.pipe(texts): #因为名词对于模型影响最大就只用NOUN noun_text = ' '.join(token.lemma_ for token in doc if token.pos_ == 'NOUN') output.append(noun_text) return output df['text'] = only_nouns(df['text']) df.head() ======================================================= text label 0 boss bag award executive business magazine tit... 0 1 copy bumper sale fi shooter game copy sale com... 4 2 msp climate warning climate change control dec... 2 3 pavey success view week race track bronze inju... 3 4 tory rethink association candidate election ag... 2
训练
1 2 3 4 5 6 7 8 9 10 11 12 13
n_topics = 5
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer vec = TfidfVectorizer(max_features=5000, stop_words='english', max_df=0.85, min_df=2) features = vec.fit_transform(df.text)
for i, topic_vec inenumerate(cls.components_): print(i, end=' ') #topic_vec.argsort() 词索引按最小分数和最大分数生成的arry #[-1:-n_top_words:-1]切片到最大15个词 for fid in topic_vec.argsort()[-1:-n_top_words:-1]: print(features[fid], end=' ') print() ============================================================= 0 growth sale economy year company market share rate price firm profit oil analyst month 1 film award actor star actress director nomination movie year comedy role festival prize category 2 game player match team injury club time win season coach goal victory title champion 3 election party government tax minister leader people campaign chancellor plan issue voter country taxis 4 phone people music technology service user broadband software computer tv network device video site
预测
1 2 3 4 5
new_articles = [ "Playstation network was down so many people were angry", "Germany scored 7 goals against Brazil in worldcup semi-finals" ] cls.transform(vec.transform(new_articles)).argsort(axis=1)[:,-1]
bunch.data[0] ==================================================================== 'I was wondering if anyone out there could enlighten me on this car I saw\nthe other day. It was a 2-door sports car, looked to be from the late 60s/\nearly 70s. It was called a Bricklin. The doors were really small. In addition,\nthe front bumper was separate from the rest of the body. This is \nall I know. If anyone can tellme a model name, engine specs, years\nof production, where this car is made, history, or whatever info you\nhave on this funky looking car, please e-mail.\n\nThanks,\n- IL\n ---- brought to you by your neighborhood Lerxst ----\n\n\n\n\n'
提取特征:
1 2 3 4 5 6 7
from sklearn.feature_extraction.text import TfidfVectorizer
vec = TfidfVectorizer(max_features=10000) features = vec.fit_transform(bunch.data) print(features.shape) ================================================================ (11314, 10000)
input_texts = ["any recommendations for good ftp sites?", "i need to clean my car"] input_features = vec.transform(input_texts)
D, N = knn.kneighbors(input_features, n_neighbors=2, return_distance=True)
for input_text, distances, neighbors inzip(input_texts, D, N): print("Input text = ", input_text[:200], "\n") for dist, neighbor_idx inzip(distances, neighbors): print("Distance = ", dist, "Neighbor idx = ", neighbor_idx) print(bunch.data[neighbor_idx][:200]) print("-"*200) print("="*200) print() ========================================================================== Input text = any recommendations for good ftp sites?
Distance = 0.5870334253639387 Neighbor idx = 89 I would like to experiment with the INTEL 8051 family. Does anyone out there know of any good FTP sites that might have compiliers, assemblers, etc.?
I am looking for ftp sites (where there are freewares or sharewares) for Mac. It will help a lot if there are driver source codes in those ftp sites. Any information is appreciated.
Thanks in -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- ========================================================================================================================================================================================================
Input text = i need to clean my car
Distance = 0.6592186982514803 Neighbor idx = 8013 In article <49422@fibercom.COM> rrg@rtp.fibercom.com (Rhonda Gaines) writes: > >I'm planning on purchasing a new car and will be trading in my '90 >Mazda MX-6 DX. I've still got 2 more years to pay o -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Distance = 0.692693967282819 Neighbor idx = 7993 I bought a car with a defunct engine, to use for parts for my old but still running version of the same car. The car I bought has good tires. Is there anything in particular that I should do to stor -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- ========================================================================================================================================================================================================


 wechat
wechat alipay
alipay