9.ELMO 论文笔记
9.ELMO 论文笔记
本文是 Deep contextualized word representations笔记.ELMO是Embeddings from Language Models的简称。

Abstract
本文作者引入了一种新的深层的上下文词表示,该模型能:
- 使用词的复杂特征
- 在不同语境下词的多义性
本文的词向量是学习深层双向语言模型的内部状态的功能得到的。作者发现这些表示能轻松加到已存在的模型上,并且在6大NLP问题上有显著的提升,像QA,文本蕴含,情感分析。还分析了暴露预训练网络的深层内部是至关重要的,这允许下游模型来混合不同类型的半监督信号。
3.1 Bidirectional language models
给定N个token的序列,,前馈语言模型在给定前的情况下来计算的概率:(LM就是一个预测下一个词的任务)
如果通过token embeddings 或 字符卷积后再输入到L层的前向LSTMs.在位置k,每层LSTM输出一个上下独立的表示为,其中(表示第几层)。最上面一层LSTM的输出被用来给softmax层预测下一个token。
反向的LM类似于前向LM,除了将输入序列反向,目标也变成预测前一个词:
这可以用类似的前向LM实现,对于反向LSTM层,给定生成的
表征为 .
这样双向LM结合了前向和反向的LM特点。目标就是最大化两者联合的对数似然函数:
作者将前、后向的token表征和softmax层参数联系起来,同时保持每个方向的LSTM参数分开。但在方向间共享些权重而不是使用完全独立的参数。
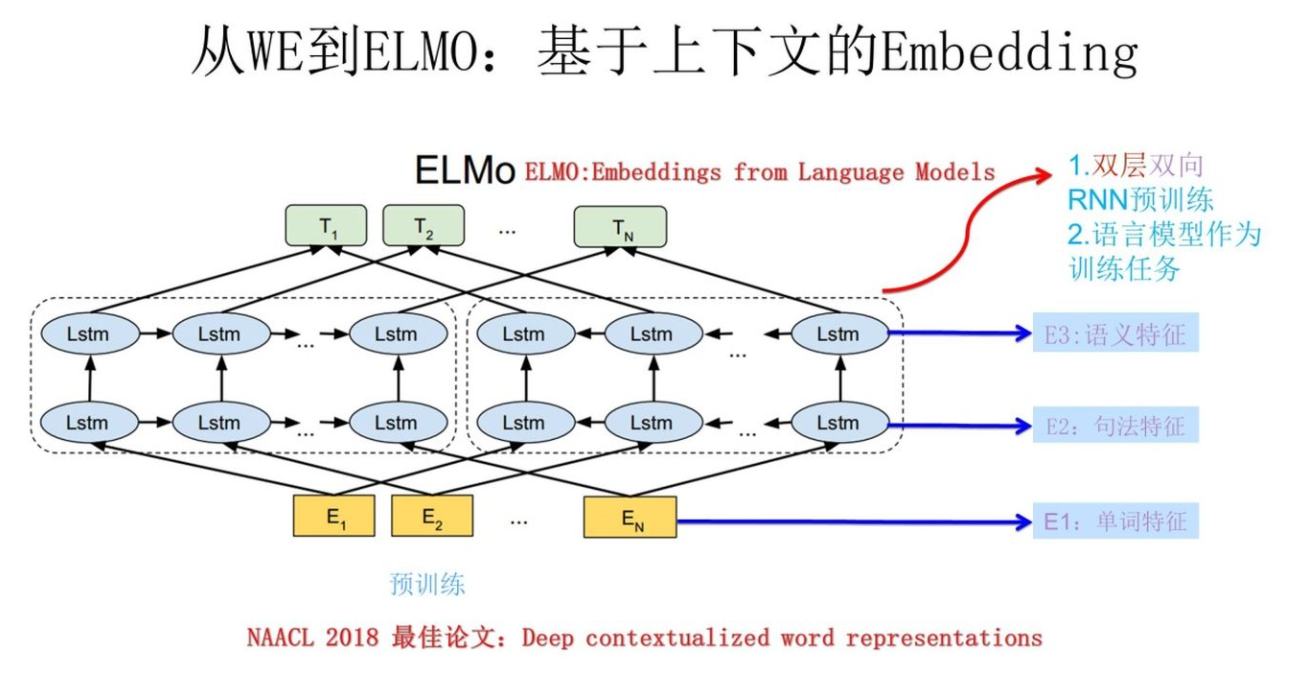
3.2 ELMo
ELMo是biLM中中间层表征的任务特定的组合。对于每个token,L层biLM计算表征的集合:
其中.当时,就是token层,因此可以简写为式4中第二行。
ELMo将所有层的(式4)压缩成单一向量,.最简单的就只选择最上面一层作为token的表示,.更通用做法是,对所有层求权重和:
在(1)中,(按论文标号)表示经过softmax-normalized权重和放缩参数允许任务模型放缩ELMo向量。这是个经验参数,也能帮助优化过程。
3.3 Using biLMs for supervised NLP tasks
给定一个预训练双向语言模型和对目标NLP任务的监督架构,这是使用双向biLM来提升任务模型是非常简单的。就是运行biLM并记录每层的每个词的表征。然后,让终端任务模型学习这些表征的线性组合。如下所述。
首先,考虑没有biLM的监督模型底层是差不多的架构,这就允许ELMo以一种固定的规则加到上面。给定一个token,使用预训练的词嵌入和选择基于character的表征形成一个上下文无关的token表征是标准的。然后,模型形成一个上下文敏感的表征,通常使用双向RNNs,CNNs或者前馈神经网络得到。(就是拿这些网络得到token表征输入到biLMs中)。
为了添加ELMo到监督模型,首先固定biLM的权重,token表征然后跟ELMo向量合并,将这个增强的表征输入到具体任务的RNN中。像SNLI,SquaD,NLP推理和问答任务。作者观察到通过引入针对具体任务的线性权重和用这个增强表征能进一步提升表现。
最后,加入dropout和到ELMo中,.
3.4 Pre-trained bidirectional language model architecture
为了在保持纯粹的基于character的输入表征的同时,平衡语言模型整体的复杂度与模型大小和下游任务的计算需求,将单个最佳模型CNN-BIG-LSTM中的embedding和隐藏层维度都减半。最后模型使用L=2的biLSTM,含有4096个units和512维度映射和一个残差连接第一层和第二层。上下文不敏感类型表征用2048character n-gram卷积后接两个高速层和一个线性映射到512的表征。结果上,biLM给每个输入token提供了3个表征,包括那些外部训练集得到的纯粹的character input。对比而言,传统词嵌入方法在固定词表上只提供一层token的表征。
4. Evalution

ELMo在大部分任务上都有大的提升。

ELMo的低层侧重于词性等语法特征,高层侧重于语义特征。上表5中是语义消歧任务,第二层要好与第一层。上表6中是POS任务,第一层要好于第二层。如下图,来自于[4].
总结
ELMo的优点:
- 利用双向的LSTM抽取word embedding,能有效解决一定程度上的一词多义。
- 基于字符:ELMo表示纯粹基于字符,然后经过CharCNN之后再作为词的表示,解决了OOV问题,而且输入的词表也很小。
- 通用性强,如文中在6大任务中都有比较好的表现。
缺点:
- 使用LSTM抽取特征,效果不如后来的Transformer。
- 使用拼接的方式来融合上下文特征,效果有限。
- 训练耗时长,RNN要等上一步隐藏状态计算完后才能开始下一步计算。
Inference
[2] NAACL2018:高级词向量(ELMo)详解(超详细) 经典
[3] 论文翻译——Deep contextualized word representations
[4] 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
[5] EMLo
 wechat
wechat alipay
alipay