6. Capsule net 论文笔记
6. Capsule net 论文笔记
本文是2017年深度学习奠基人Geoffrey Hintons的 Dynamic Routing Between Capsules笔记。
摘要
一个capsule胶囊是一组神经元,其激活向量(就是低层的输入向量)表示的是特定类型的实体(如对象或对象的部分)的实例化参数。本文使用激活向量的长度来表示实体存在的概率和其方向来表示实例化后的参数。活的胶囊通过变换矩阵在低一层做预测,然后作为高层胶囊的实例化参数。当多个预测一致时,高层胶囊激活。本文在求低层到高层胶囊的权重时没有使用反向传播,而使用动态路由来更新:低层胶囊偏好将其输出传送到高层胶囊,使其激活向量和预测值的点积值较大。
胶囊网络计算过程

上图来源于 Understanding Hinton’s Capsule Networks. Part 2. How Capsules Work..
Step1: 预测向量。
如上图左侧表示低层胶囊输入,表示胶囊数目。图示就是3个,表示每个胶囊激活向量的长度。比如表示眼睛这种低层胶囊特征,(其它向量分别表示鼻子、嘴巴等特征用来检测人脸),作者会将其转换成所谓的预测向量,就是乘以一个转换矩阵:
这个矩阵是通过反向传播学习的。
Step2: 高层胶囊输入。
然后将得到的预测向量进行加权求和:
这就是图示“求和“符号部分的数学表示,其中是权重系数,论文中叫耦合系数(coupling coefficients),由动态路由算法决定。并且要满足。其表示低层胶囊对高层胶囊的权重大小。这样,作者就得到了高层胶囊的输入。
coupling coefficients that are determined by the iterative dynamic routing process
Step 3: 高层胶囊输出。
如图示Squash函数部分,即将得到的输入经过squash函数获得输出。因为胶囊网络是拿胶囊的向量的模长来表示高层胶囊表示的实体存在的概率。因此,论文提出了非线性函数squashing。其可以保证短向量压缩趋于0,长向量趋近于1,并且保持向量方向不变。
use a non-linear “squashing” function to ensure that short vectors get shrunk to almost zero length and long vectors get shrunk to a
length slightly below 1.
- 当是一个长向量,那么
- 当是一个短向量,那么
squash函数1D可视化图如下:(可以看看其趋近值)

1 | import torch |
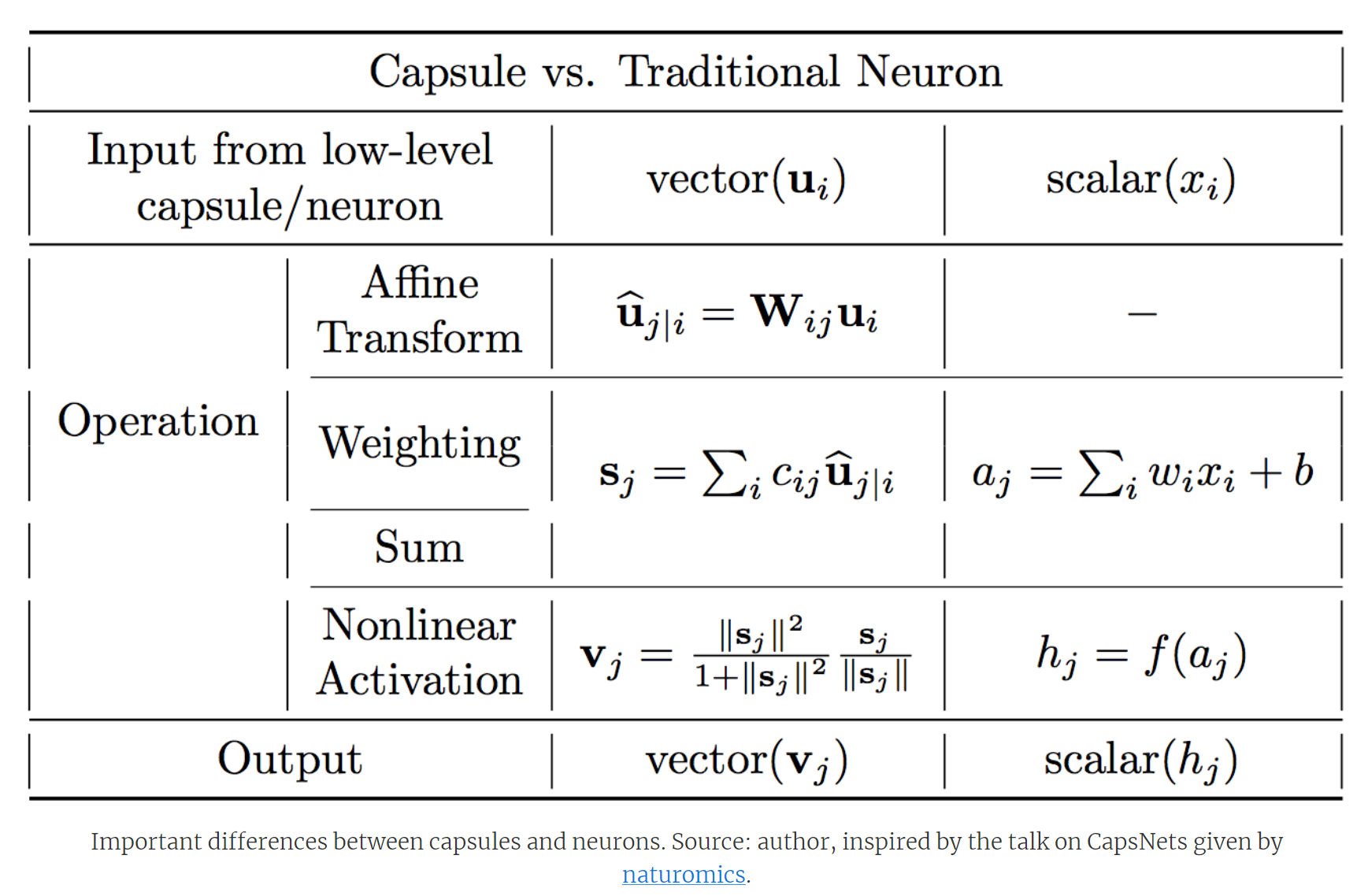
贴个胶囊网络和普通神经网络的区别表:(也来自于[1])。
注:胶囊网络胶囊输入是向量,神经网络神经元输入是标量。
现在经过3个步骤梳理作者大概知道高层胶囊输出是怎么计算的。转换矩阵可以用反向传播算法学习得到,但第二步中
耦合系数是通过所谓的动态路由算法来更新的,那么到底是怎么计算的呢?
动态路由算法
动态路由算法伪代码:

按照行号逐一解释:
- 定义算法输入:低层,(因为胶囊网络也是多层的,它的高层输入来自于低层的输出);该低层所有胶囊的输出,(就是低层胶囊经过转换矩阵变换成的向量输入到高层胶囊; 以及路由迭代次数(超参数,一般设置为3,或4).
- 定义一个临时变量,初始化为0.用于迭代计算低层胶囊中胶囊到高层中胶囊.
- 迭代次.
- 将经过softmax转换为总和为1的类概率权重,其实,第一轮都相等.高层胶囊数目, (按照最大熵也应该是这样).
- 按照上面式2,作者就可以求出高层胶囊输入.
- 类似地按照式3求出高层胶囊输出.
- 将更新为.因为如果是正值且越来越大的话表示与越来越相似。(这个过程也有点类似于聚类,如李宏毅教授Capsule)
最后返回高层胶囊输出.给个简化示例:
1 | def dynamic_routing(x, num_caps, dim_caps, routings=4): |
Inference
[1] Understanding Hinton’s Capsule Networks
[2] Dynamic-Routing-Between-Capsules
[3] 浅谈胶囊网络与动态路由算法
[4] capsule-network
 wechat
wechat alipay
alipay