5.HAN 论文笔记
5. HAN 论文笔记
来自于Hierarchical Attention Networks for Document Classification 论文。
摘要
本文提出一种层次attention网络用于文档分类。该模型有两个特别的特点:(i) 其采用层次结构来翻译文档的层次结构。(ii) 在词-句子层次应用两种层次的的注意力机制,当构建文档表示时使其能以不同的注意力来关注越重要或越不重要的的内容。在六个大型文本分类任务进行的实验证明了,提出的架构有大幅度提升,优于之前的方法。可视化注意力层表明模型选择了信息丰富的词和句子。
1.介绍
文本分类是NLP中的一个基本任务。目标是给文本分配标签。广泛应用包括主题标记,情感分类,和垃圾邮件检查。文本分类的传统方法用稀疏的词汇特征来表示文档,如n-grams,然后在该表示上用线性模型或核方法来分类。最近的方法多使用深度学习,如CNN和基于LSTM的循环神经网络来学习文本表示。
作者只要贡献是一个新的架构,层次注意力网络Hierarchical Attention Network (HAN),设计用来获取关于文档结构的两个基本的直觉。首先,因为文档有层次结构(词组成句子,句子组成文档),作者同样构建文档表示,即第一步构建句子的表示然后聚合这些句子表示来表征文档。第二步,观察到在文档中不同词和句子是有不同信息的。并且,词和句子的重要性高度依赖上下文,如,在不同上下文中,同样的词或句子可能重要性不同 (3.5节Context dependent attention weights 中会介绍)。为了包括对该事实的敏感性,作者模型包含两个层次的注意力机制——一个是在word level 另一个在sentence level——这让该模型在构建文档表征是自动给予更多或更少注意力给独立的词或句子。为了说明这个机制,如下图Fig.1实例,其是一个简短的Yelp 评论,任务是根据评论预测1-5星的评级。直觉地,第一、三句在帮助预测星级上有更强的信息;在这些句子中,包含在该评论中的词 delicious,a-m-a-z-i-n-g贡献了更多暗示积极态度的信息。注意力提供两个好处: 它不仅通常带来更好的表现,而且还可以提供哪些词和句子对于分类决策有帮助的直觉,这在应用和分析中是非常有价值的。

关键区别于之前工作是HAN用上下文来发现什么时候一个序列的token是相关的而不是简单地从上下文中过滤这些token。为了评估该模型表现,对比其他常见文本分类架构,在第3部分中的6个数据集上测试。该模型大幅度优于之前方法。
2. Hierarchical Attention Networks
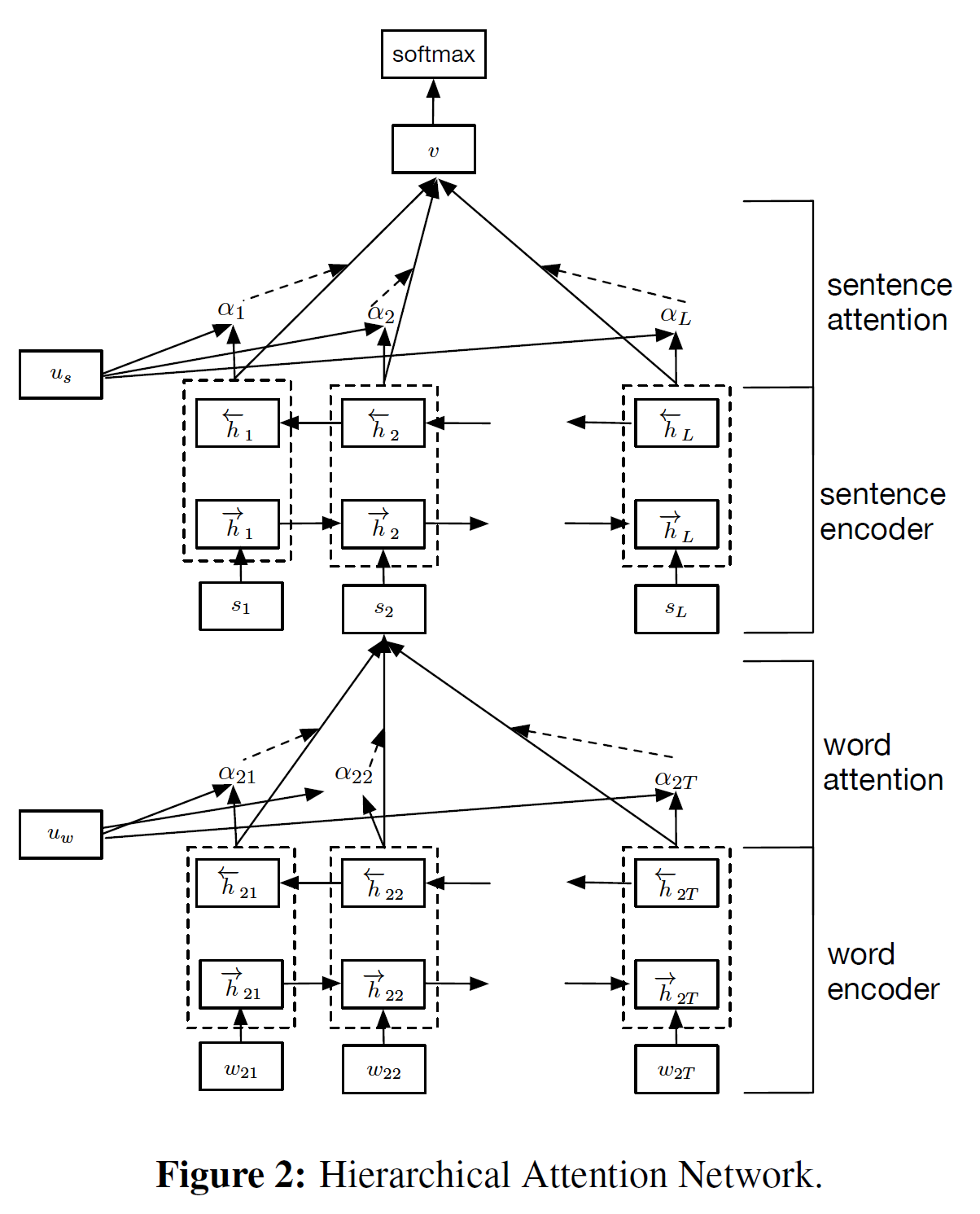
HAN整体结构如下图Fig.2所示。包括几个部分: 一个词序列编码器,一个词级别注意力层,一个句子编码器和一个句子基本注意力层。接下来详细介绍。
2.1 基于GRU的序列编码器
GRU使用门控机制追踪序列状态而不是使用独立的记忆cells。其有两种类型的门控:重置门和更新门。(具体看以前这篇)这两个门一起控制多少信息来更新状态。在时刻,GRU计算新的隐藏状态为:
前一时刻隐藏状态当前时刻新的隐藏状态直接是线性插值关系。更新门
决定多少以前信息保留还是多少新信息添加。的更新公式如:
(就是输入与点乘再加上更新的隐藏信息,即与上一时刻隐藏状态点乘。再加个偏置整体过sigmoid函数。)
其中是时刻的序列向量。候选状态用类似于传统RNN计算:
(输入与点乘后再加上重置门控制的上一时刻隐藏状态信息流入,加个bias;再过tanh函数)。
这里是重置门,控制过去隐藏状态多少流入候选隐藏状态。如果为0,就丢掉过去状态。重置门更新公式如:
2.2 层次注意力
本节将集中讲述文档-级别分类任务。假定一个文档有个句子,并且每个句子有个词。词,其中代表词在第个句子中。提出的模型(HAN)将原始文档映射成一个向量表示,在该向量表示上构建一个分类器来做文档分类。接下来,作者将展示怎样使用层级结构从词向量来逐步构建文档级别的向量。
Word Encoder 给定一个由词组成的句子,。首先将词embed成向量,就是通过一个embedding 矩阵。这里使用双向GRU通过前后两个方向来汇总单词信息来获取单词的注释,因此能将上下文信息包含在注释中。双向GRU包含前向GRU 记为 (因为现代文本一般是从左向右读一行, 在批次处理embedding 词向量时将这个顺序的输入看作前向), 其读取句子从词到,后向就是反方向读取。那么有:
作者通过合并给定词前向隐藏状态和后向, 如,这汇总了中心词的周围的上下文句子信息。
注: 就是Fig.2中的word encoder部分。
式4中,
- 第一个式子代表前向从1到T个词的embedding 后的;
- 第二个式子是前向从1到T个词的GRU的隐藏状态
- 第二个式子是后向从T到1个词的GRU的隐藏状态
Word Attention
并非所有的词都对句子意义的表示有同等贡献。因此,引入注意力机制来提取,对句子意义表征重要的词,并合并这些重要信息的词表征来构成句向量。具体地,
亦即,
- 首先“喂”入词注释到一层MLP得到来作为的隐藏状态表示,
- 然后将词的重要程度衡量为与上下文向量的相似度,
- 并将其通过softmax函数归一化得到重要性权重
注: 上面这三句话代表式5中前2个公式。
最后,基于上面的权重对词注释求权重和得到的值作为句向量(这儿有点滥用记号了).(就是式5最后一个公式)上下文向量可以看做是一个固定的query代表着“什么是信息性词”而不是平常被用在记忆网络中的词。这个向量是随机初始化后然后在训练整个网络中得到的。
式4中3个公式,pytorch代码实现如下:
1 | class SelfAttention(nn.Module): |
Sentence Encoder
这部分跟Word encoder类似,就不会详细介绍了。
上面得到了句向量, 过双向的GPU来编码该句子:
然后作者合并得到两个句注释得到该句子的注释。这个句子注释汇总了句子邻近的句子信息但仍然聚焦在句子上。
Sentence Attention
还是利用注意力机制,将得到的句子注释过MLP线性映射后过函数得到其表示向量。然后计算其余上下的邻近句子向量的注意力分数,最后求与句子注释的权重和。
最后得到的文档向量汇总了一个文档中所有的句子信息。其中也是随机初始化后联合训练得到的。
2.3 文档分类
文档向量是文档的高层次表征,用来做分类特征:
分类损失:
其中是文档d的标签。
 wechat
wechat alipay
alipay
