4. Fasttext 分类器论文Bag of Tricks for Efficient Text Classification
4. Fasttext 分类器论文Bag of Tricks for Efficient Text Classification
Abstract
本文意在探索一种简单又有效的文本分类基准。实验证明了fast text 分类器 fastText在准确率上表现几乎与一些深度学习模型不相上下,并且在训练和评估上快很多。fastText可以使用标准多核cpu上训练大于10亿词汇,训练时间小于10分钟,并且区分312K类别的50w条句子用时少于1min。
1. Introduction
文本分类在NLP许多应用上是非常重要的任务,如搜索,信息检索,排序和文档分类。近来,基于神经网络建模变得越来越受欢迎。虽然,在实际中这些模型取得不错的表现,它们在训练和测试时,变得相对较慢,限制在于其使用非常大的数据集。
与此同时,线性分类器经常被看作文本分类任务的baseline。尽管它们很简单,如果特征使用合适的话也能取得非常好的表现。其也有潜力拓展到非常大的语料上。
在本文中,探索如何将这些baseline,在文本分类的上下文中,拓展到有巨大输出空间的非常大的语料库上。受到近期成果,有效词表示学习启发,作者证明了有等级约束和快速损失近似的线性模型在10亿词汇上能10分钟内训练完,并且跟最小成果取得相当的表现。在两个不同任务上评估fastText的质量,分别是命名标注预测和情感分析。
2. 模型架构
简单和句子分类的有效基准是表示句子为BoW并训练为一个线性分类器,如logistic 回归或SVM。然而, 线性分类器不共享类别间的特征参数。当一些类别只有少量样本时,这可能限制其生成大的输出空间的上下文。该问题的通用解决方案分解线性分类器为第等级矩阵和使用多层神经网络。
图1展示一个简单的有等级约束线性模型。第一个权重矩阵A是所有词汇的查询表。词表示经过平均后得到文本表示,接着喂进线性分类器。文本表示是一个隐藏能潜在被利用的变量。该架构类似于MIkolov的cbow, 不过这里中间词被标签代替。(就是预测中心变成了预测文本标签)。 使用softmax 来计算所有预定义类别的概率分布。对应 个文档集,最小化所有类别负的对数似然:
其中, 是标准化后 n个文档的特征 (词向量), 是标签, 是权重矩阵, 是softmax函数。 这个模型异步地训练在多个CPU上,使用线性衰减学习率的SGD。

2.1 层次softmax
当类别数目很大时,计算线性分类器非常昂贵。更具体地,计算复杂度是,其中是类别数目, 是文本表示的维度。为了减少计算时间,使用基于哈夫曼编码树的层次softmax。
在训练时, 计算复杂度将掉到.
在测试时搜索大部分可能的类别,层次softmax也具有优势。每个节点分配一个概率,表示从根到该节点的路径的概率。如果节点在深度, 父节点为,其可能的概率是:
这意味着节点概率总是小于其父节点。用深度优先搜索树,并追踪叶子间最大的概率,使得作者能抛弃任何与相关小概率的分支。实际上,作者在测试时观察到复杂度降为。 该方法使用二叉堆进一步拓展,计算前T个目标计算代价为。
2.2 N-gram features
词袋忽略词的顺序,但是考虑词的顺序往往计算代价高昂。而本文使用n-grams集合作为附加的特征来获取一些局部的词的顺序信息。实际中这非常有效也取得了跟直接使用词序差不多的结果。
通过使用hashing trick方法,实现了一种快速且空间利用率高的n-grams空间映射。
3. 实验
在两个不同任务上评估fastText.
- 在情感分析问题上,拿它和已存在的文本分类器比较
- 评估其容量以便拓展到标注预测数据集的大的输出空间上。这里,模型可以使用
Vowpal Wabbit库实现,但在实际观察中,专门实现可以快2-5倍。
3.1 情感分析
数据集和baselines 使用了8个数据集并按照Zhang的评估指标。选取了来自Zhang的n-grams和TFIDF baselines ,也有character level convolutional model (char-CNN)字符级卷积模型,字符级卷积循环网络 char-CRNN,very deep convolutional network (VDCNN)非常深的卷积网络作为对比模型。
表1是:在8个数据集上测试准确率的比较。

表2:训练一轮时间比较,fastText和 char-CNN、VDCNN

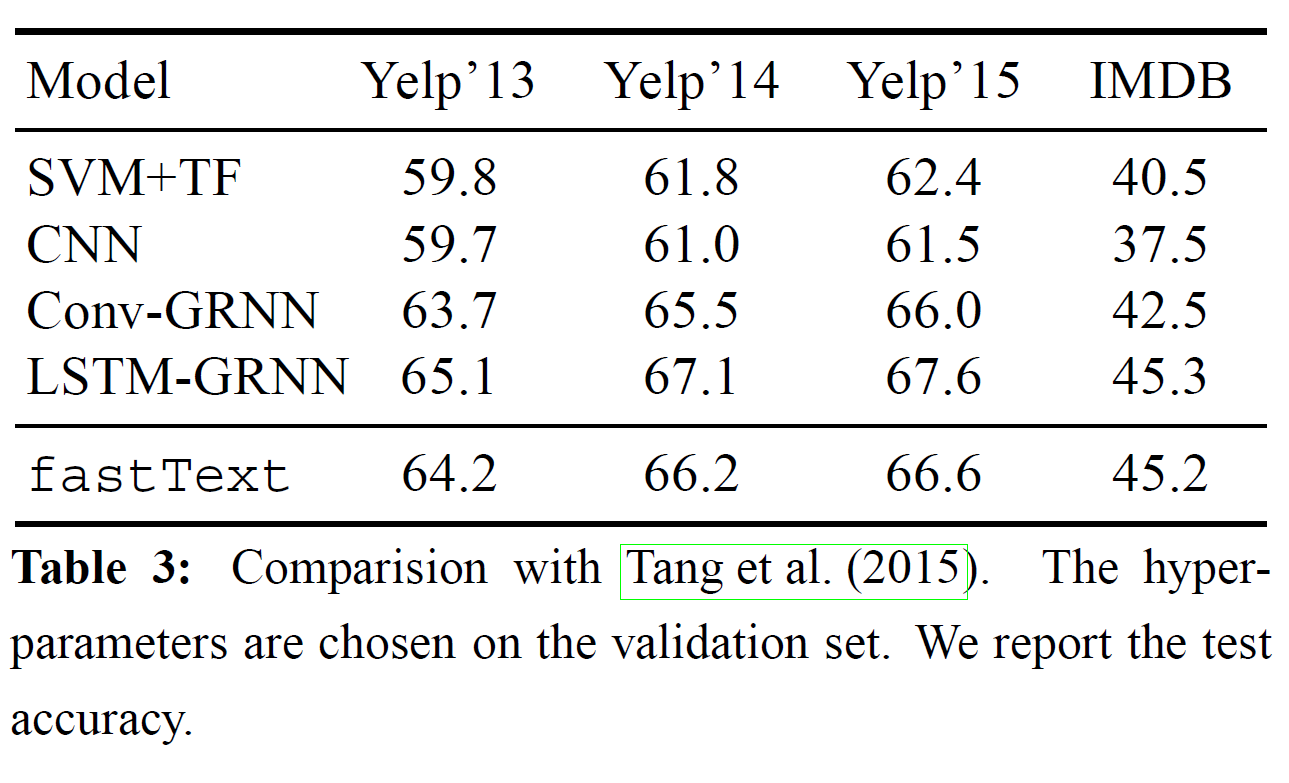
表3:测试准确性比较
our method is competitive with the methods presented in Tang et al. (2015). We tune the hyperparameters on the validation set and observe that using n-grams up to 5 leads to the best performance. Unlike Tang et al. (2015), fastText does not use pre-trained word embeddings, which can be explained the 1% difference in accuracy.
fastText跟Tang的模型方法比较。在验证集上,调试超参数n-gram为5时表现最好。不像Tang,fastText不使用预训练词嵌入,准确性只有1%的差。
3.2 标注预测
在YFCC100M数据集上,结果如下:

实验结果如下:比较小的隐藏层效果就差不多,加上bigram效果会好点

4. 讨论和结果
提出了一种简单的文本分类方法。不像非监督的word2vec训练词向量,作者的词特征能平均后合在一起构成良好的句子表示。在几个任务中, fastText获得了跟受深度学习启发提出的方法差不多的效果,而且更快。尽管深度神经网络在理论上有比浅层模型更强的表示能力,不清楚如果简单的文本分类问题像情感分析是合适的任务来评估它们。作者公开了代码以便研究机构能在作者工作上面轻松搭建。
Inference
[1] Word Embedding Papers | 经典再读之fastText
[2] fasttext论文
 wechat
wechat alipay
alipay
