Precision Recall F1-score和AUC 评价指标解释
Precision Recall F1-score和AUC 评价指标解释
1. Precision, Recall, F1-score解释
这些名词都建立在混淆矩阵之上confusion matirx,如下所示:
| 真实情况 | 预测Positive | Negative |
|---|---|---|
| 正例 | TP 真正例 | FN 假反例 |
| 反例 | FP 假正例 | TN 真反例 |
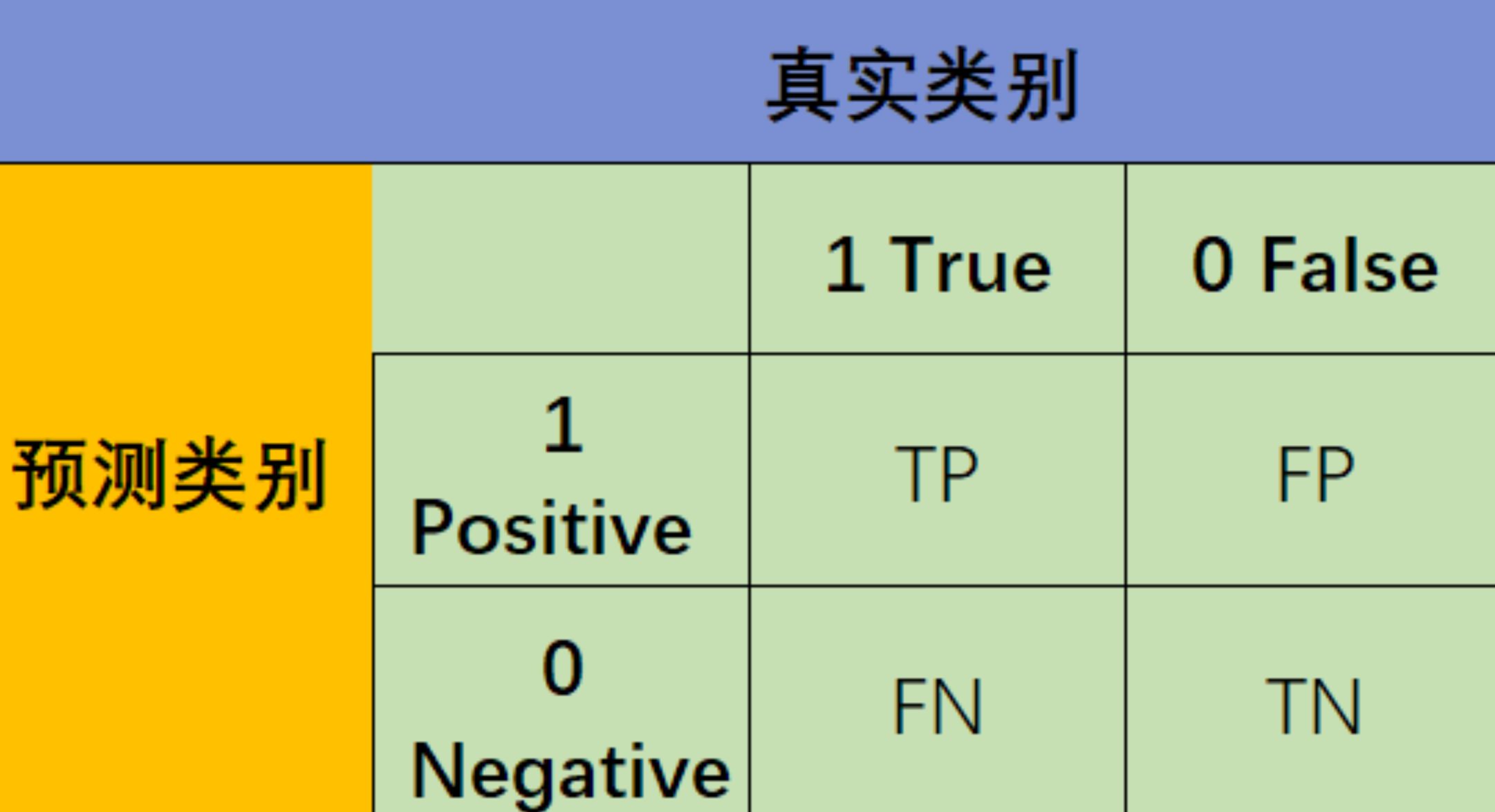
查准率和查全率分别为:
查准率:就是找到的正例中有多少是真正的正例(实际上是比率),就等于真正的正例/ 所有预测的正例
查全率:又叫召回率, 就是在找到的真正例在所有原始样本中的比例,(所有原始样本数目=真正例和反例和),在混淆矩阵中就是$TP + FN$,实际上就等于真正的正例/所有原始样本数。更通俗地说,把目标样本找全了没,而查准率是你找准了多少正样本。
而F1-score是:它是P和R的调和平均:
Macro-F1和Micro-F1
- Macro-F1和Micro-F1是相对于多标签分类而言的。
- Micro-F1,计算出所有类别总的Precision和Recall,然后计算F1。
- Macro-F1,计算出每一个类的Precison和Recall后计算F1,最后将F1平均。
代码示例:
1 | def f1(actual, predicted, label): |
Keras实现 Keras Macro F1-Score Implementation:
1 | import tensorflow as tf |
2.ROC 和 AUC
Receiver operating characteristic wiki有全面的介绍。 AUC(Area Under the ROC Curve)指标是评估二分类模型的另一个重要指标,它的计算方法是先画出ROC曲线,然后计算曲线下面积。ROC曲线的横轴是False Positive Rate(FPR),表示实际为负类的样本中被预测为正类的比例;纵轴是True Positive Rate(TPR),表示实际为正类的样本中被预测为正类的比例。AUC的取值范围在0.5和1之间,越接近1表示模型的性能越好。
在使用这两个指标进行模型评估时,通常会计算它们在验证集或测试集上的平均值作为模型的最终指标,以便于不同模型之间的比较。
ROC曲线又称, “受试者工作特征——ReceiverOperating Characteristic”。与P_R曲线使用P, R为纵横坐标不同,ROC使用的是:(以FPR为x轴,TPR为y轴画图,就得到了ROC曲线)。像表1和图1所示,在二元分类任务中,一般将正例样本预测为正例称为True Positive(TP),将负例样本预测为正例称为False Positive(FP),将负例样本预测为负例称为True Negative(TN),将正例样本预测为负例称为False Negative(FN)。
- 纵轴:
TPR True Positive Rate简称TPR,正确分类的正样本在所有正例样本中占比,即表示实际为正例并被正确地预测为正例的样本占所有实际为正例样本的比例,其计算公式跟Recall一样。也称为Recall或Sensitivity。 - 横轴:
FPR False Positive Rate简称FPR,FP在所有负例样本中占比,也可以说是所有负例样本预测为正例的,即表示实际为负例但被错误地预测为正例的样本占所有实际为负例样本的比例,即:。(误分嘛,把正的分类成负的——FP, 把负的分类成正的——TN。)
计算公式为:
对照上面混淆矩阵图示,
- TPR就是针对1这列计算,TP除以1这一列的和
- FPR就是针对0这列计算,FP除以0这一列的和
将同一模型每个阈值 的 (FPR, TPR) 座标都画在ROC空间里,就成为特定模型的ROC曲线
ROC曲线下方的面积(英语:Area under the Curve of ROC (AUC ROC)),其意义是:
- 因为是在1x1的方格里求面积,AUC必在0~1之间。
- 假设阈值以上是阳性,以下是阴性;
- 若随机抽取一个阳性样本和一个阴性样本,分类器正确判断阳性样本的值高于阴性样本之几率 =AUC=AUC[1]。
- 简单说:AUC值越大的分类器,正确率越高。
Inference
[1] 一文读懂分类算法常用评价指标
[2] 精确率、召回率、F1 值、ROC、AUC 各自的优缺点是什么?
[4] 评估分类模型
[5] F1分数(F1 Score)详解及tensorflow、numpy实现
[6] computing-macro-average-f1-scor
[7] AUC的面试
 wechat
wechat alipay
alipay