机器学习-白板推导 10. EM 算法
机器学习-白板推导 10. EM 算法
1. EM算法导出
本文中所有的参数定义如下:
EM是Expectation Maximization简写,意为期望最大, 用于含有隐变量的概率模型参数的极大似然估计。我们经常说的极大似然估计是对于概率分布,求解使得其最大的算法:
对于式1如果引入隐变量,要满足.如果是离散量就改成求和。那么可改写成:
实际上式2是非常难计算,因为有未观测数据并含有积分的对数。
而对利用条件概率有:
其中,引入的是关于的分布。
现在对式3左右两边同时求关于的期望:
右边变成:
其中,前半部分是ELBO,evidence lower bound。后半部分是。
KL散度是用来衡量两个分布相似度(距离):
因此,。根据式3, 4, 5可知,当KL部分取等号时,,也就是说ELBO是其下界。
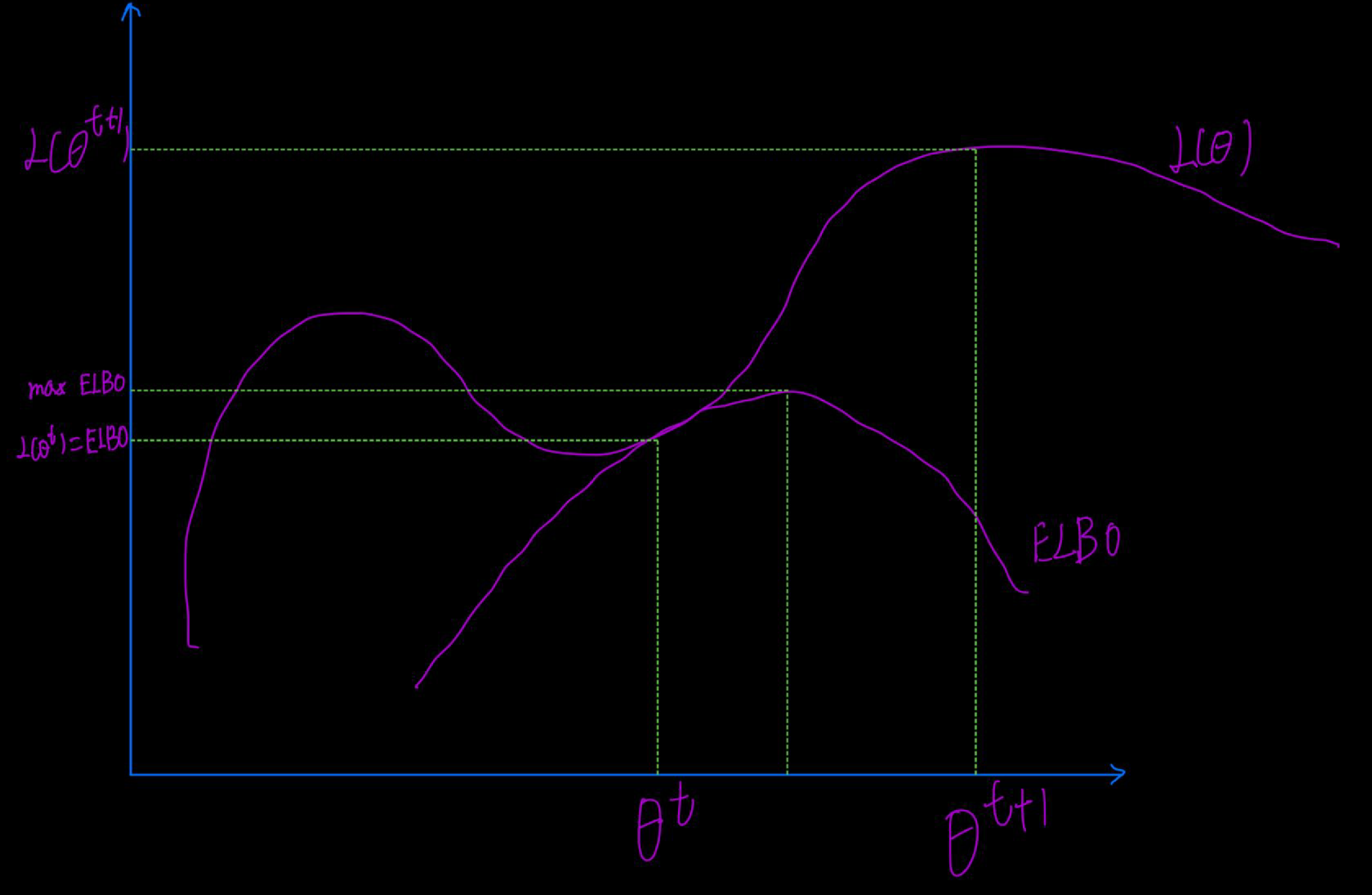
如上图所示,和ELBO都是关于的函数,且从定义上看,,也就是图像总在ELBO上面。我们用迭代法来寻找最优解,当前仅当时,能使得,并且因为迭代法要求使得。实际上,先赋予初值,求出ELBO的期望,然后求下一个,直到ELBO值大于对应的,用替换掉,直到找到最大的参数,这时也是最大的参数。其公式就是:
总结:EM算法适用于含有隐变量的极大似然估计,由于含隐变量的的积分和对数难于计算,转化为求ELBO的最大值,EM算法公式如下:
最重要的两步:
- E step: 计算在概率分布下的期望。
- M step: 计算使得这个期望最大化的参数。
2. EM 公式导出另外一种方法 (Jensen 不等式)
对公式2引入隐变量分布:
其中,最后一步是利用Jensen不等式,对于凹函数。其实最后结果就是ELBO。当且仅当时,可取等号。
这表明引入要等于后验分布。而这时,优化目标,其它迭代优化过程跟第一小节一样。
3. EM算法的收敛性
使用迭代算法来求的最大值,即我们希望新的估计值能使得变大,就是,其中是t次迭代后的值,这跟第一小节推导非常类似。
而要证明,我们先用条件概率公式转换下:
我们对式10两边同时求关于的期望:
其中,。而右边有:
我们将前半部分记为在EM算法中称为Q function, 其实就是上面ELBO,也就是EM算法迭代目标式。
后半部分记为。那么根据式10、11和式12有:
对于,由小节1可知,那么会怎么变化?
其中,不等号变换使用Jensen不等式,如下式:
如果用KL散度易知,
那么根据式14可知,,也就是说是递减的。综上根据式13可知,是递增的,即,因此EM算法是收敛。
4. 广义EM算法
还是回到最开始的问题:最大化似然函数如式1所示。EM算法是为了解决参数估计中的问题,也就是learning问题:
实际过程中,由于难于计算,我们利用条件概率公式将其转化为式3所示。从第一小节,式3, 4, 5可得:
这里我们定义ELBO为:
另外,再写出KL散度部分:
前面部分,我们直接假定,实际上这个后验也是难以处理的。广义EM算法思路是:
先把固定住,若Q越接近P,KL部分越小,由于这时是定值,那么ELBO就会越大。即根据下式,求出
固定, 就是第一步求解的值,按照求解.
综上,广义EM可表示为:
- E-step:
- M-step:
对ELBO进一步化简有:
在前面的狭义EM算法中,只对进行迭代优化,是因为我们假定是已知的,优化与部分无关。
5. EM的变种
上节介绍了广义EM算法,其中E步和M步都是求极大,也称为MM算法。这两步求解中,先固定一个参数,再优化另外一个参数;完成后,再固定优化后得到的参数,然后优化开始固定的参数,这叫做坐标上升法。SVM中求解算法SMO就是用该方法求解的。
实际过程中, 会采用变分推断(Variable Inference)或MCMC,结合EM算法就变成了VBEM(Variable Bayes)/VEM 和MCEM。
总结:
- 狭义EM算法:迭代求解算法目标式即极大似然函数的下界ELBO:
其中,E步是计算在概率分布下的期望,M步是最大化该期望。
- 广义EM算法:不假定, KL散度部分不可忽略,求解极为困难,我们使用坐标上升法求解E步和M步:
- E步,固定 ,最大化,这时得到Q
- M步,固定Q,再最大化,得到。
Inference
[1] EM 算法
[2] EM算法推导与三硬币模型
[4] 人人都懂EM算法
[5] EM
 wechat
wechat alipay
alipay
