机器学习-白板推导8 指数簇分布
机器学习-白板推导8 指数簇分布
1. 指数簇分布背景
指数簇分布(Exponential Family Distribution)需要满足以下形式:
其中:
: 自然参数(natural parameter,也叫正则参数 canonical parameter)
: 充分统计量(sufficient statistic),常使用的有,一般是一个对样本的统计函数表示。
接下来会重点介绍的 是一个对数配分函数(log partition function)。
如这里的z就是归一化因子,又叫配分函数。
对两边同时取积分:
那么为什么叫log配分函数呢?
又因为
所以因此称为配分函数 ,称为对数配分函数。
本质上扮演了归一化常数(normalization constant)的角色,也就是确保 $p(x| \eta)$ 的和或者积分等于$1$。
如果给定那么就定义了被参数$\eta$控制的一个分布簇(或者集)。改变$\eta$,我们能得到这簇中的不同分布。
指数簇分布有:
- Gaussian 分布
- 伯努利分布
- 二项分布
- 泊松分布
- Beta分布
- Dirichlet分布
- Gamma分布
指数簇分布有如下性质和应用:
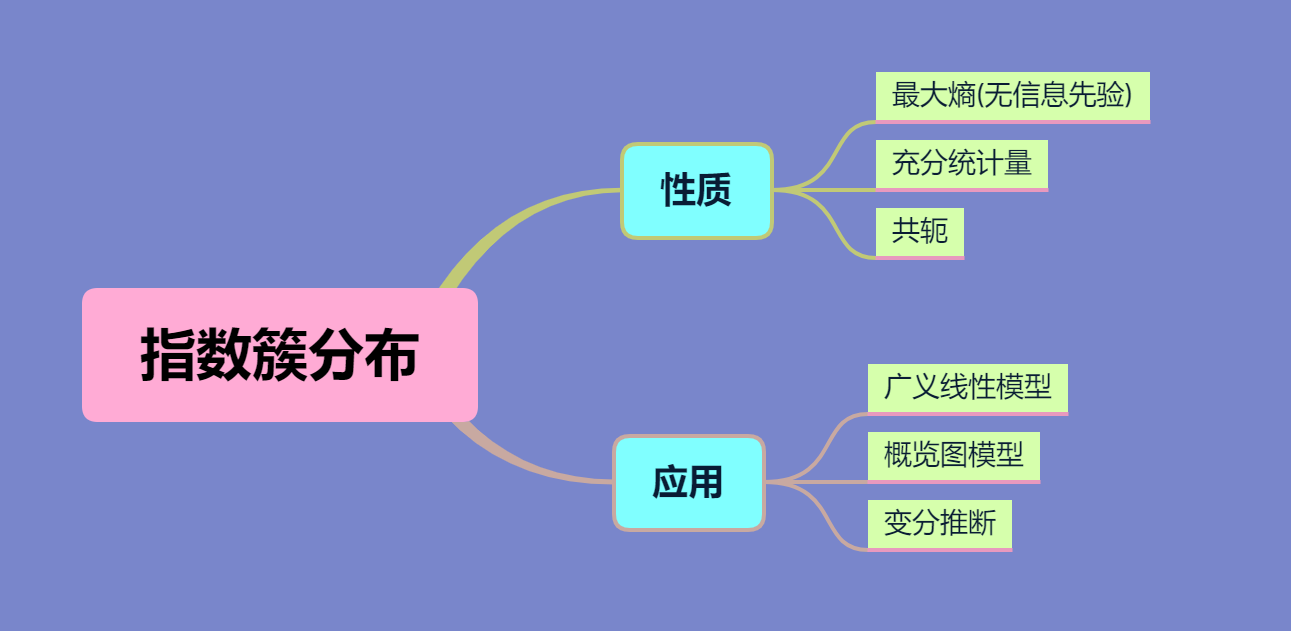
性质:
充分统计量
举例来说就是,对于一些从高斯分布中抽取出来的样本,设其充分统计量为,
那么我们就可以通过这个充分统计量来计算出均值和方差,从而明确其分布。这时就可以将样本丢掉,来节省空间,对online learning有重要作用。
共轭:因为贝叶斯公式中分母如下:
计算积分复杂或者得到的形式复杂太难计算,因此求也是很困难的,所以人们想了很多办法,如近似推断(变分推断,MCMC等)都是因为上述计算难。
共轭的概念是指给定一个特殊的似然函数的情况下,后验与先验会有一个形式相同的分布,这就解决了上述积分困难的问题,避免求分母的积分项,在后验概率正比于似然 × 先验概率概念下有如。
最大熵
最大熵原理:
当给定一个限制条件的情况下,对于未知部分,我们假设它们等可能发生,但我们无法定量分析。而熵可以进行定量分析,我们去求解最大熵,熵越大则随机性越强。
无信息先验:
在贝叶斯估计中,我们往往需要给先验一个参数,有如下方法:
①共轭:为了计算方便
②利用最大熵思想:从最大熵的角度给予先验的参数(无信息先验)
③Jeffreys’s prior
2. 高斯分布指数簇形式
将高斯分布转换成式1指数簇这种形式:
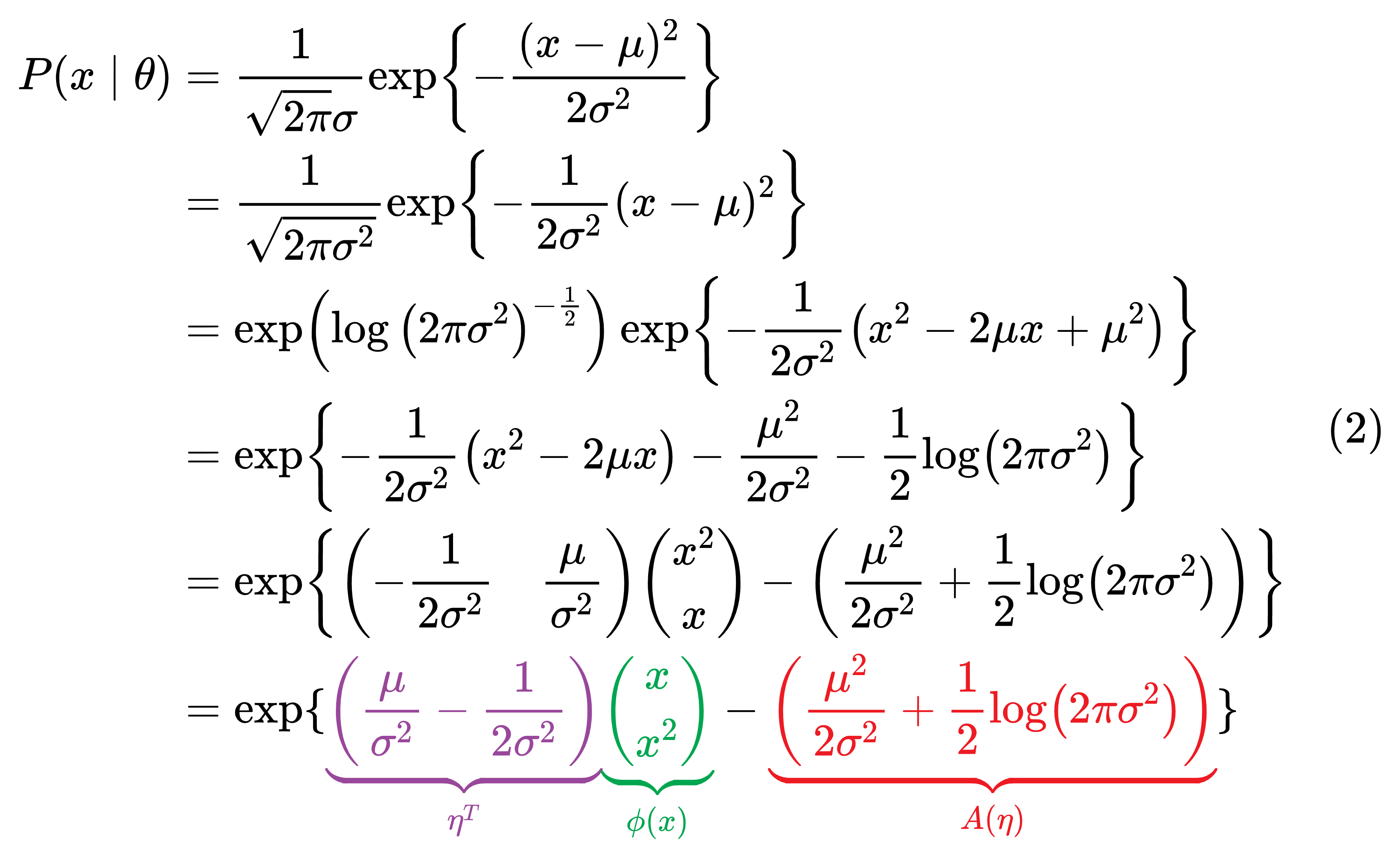
由式2中我们可以得到两个式子:
现在也要用来表示,由式3可得:
式4代入到有:
现在就得到了高斯分布的指数簇形式:
更进一步来理解指数簇表示就是:的指数形式的表示,其中前半部分是一个参数和对于该分布的充分统计量,后半部分就是再减去一个对数配分函数,并且在1小节中,我们知道如果将其转换到指数外面就是除以一个配分函数,实际上,后半部分本质上是一个归一化因子。
3. 对数配分函数与充分统计量的关系
按照式1中指数簇分布表示有:
对式7两边变量求导得:
那么就得到了对数配分函数和充分统计量的关系:
继续对式9中的求导得:
由于方差不为负,所以是凸函数。
使用第2小节高斯分布来验证:
直接可证明:
因为,关于方差期望公式。
而我们对中求导可得:
这就验证了式8和式10,我们可以看到对数配分函数的一阶导就是充分统计量量中的期望,二阶导就是方差。
4. 极大似然估计与充分统计量
若我们有数据集如下:
那么我们可以用极大似然估计来估计:
对式11最后一步求导得:
那么就可以通过求反函数来实现。这也说明就是充分统计量,我们得到 就可以求出,进一步就得到所有的需要统计参数。
5. 最大熵
在信息论中,信息量就是概率的导数取对数,即。熵就是对信息量的期望,因此,
我们先看看离散变量的最大熵:
对于离散变量要求其熵最大,即:
用拉格朗日乘执法求解:
对求导得:
那么. 其总和概率为1,因此离散概率分布是均匀分布且.
从上述推导中看出,在离散随机变量中,均匀分布熵最大。即正在没有任何已知约束的情况下,均匀分布会使得熵最大。
最大熵原理:
上面是没有任何已知信息情况下最大熵的推导,结果是要满足均匀分布。若我们已知数据集呢?比如数据集D:
然后根据数据我们可以得到其经验分布:
接下来我们就可以得到其期望, 方差, ….。把情况一般化,变量推广到函数向量,如:
其中,是假定的已知量。
现在,我们就可以在满足上述条件下,求其最大熵,这个优化问题如下:
用拉格朗日乘子法:
对每个求导, 并且,那么:
注:在求导时,只是对单独的求导,遇到时,结果为0, 可忽略。
式19中,我们看到最大熵要求分布满足指数簇分布,在满足既定数据的情况下,最大熵对应着要求满足指数簇分布。
Inference
[1] 最大熵模型理论及NLP应用总结
[2] “共轭分布”是什么?
 wechat
wechat alipay
alipay