Lecture 10 More on the SVD in Machine Learning
Lecture 10: More on the SVD in Machine Learning including matrix completion
1. SVD in machine learning
- Dimensionality Reduction(PCA)
- Principal Components Regression
- Least Squares
- Matrix Completion
- PageRank
2. Least Squares & SVD
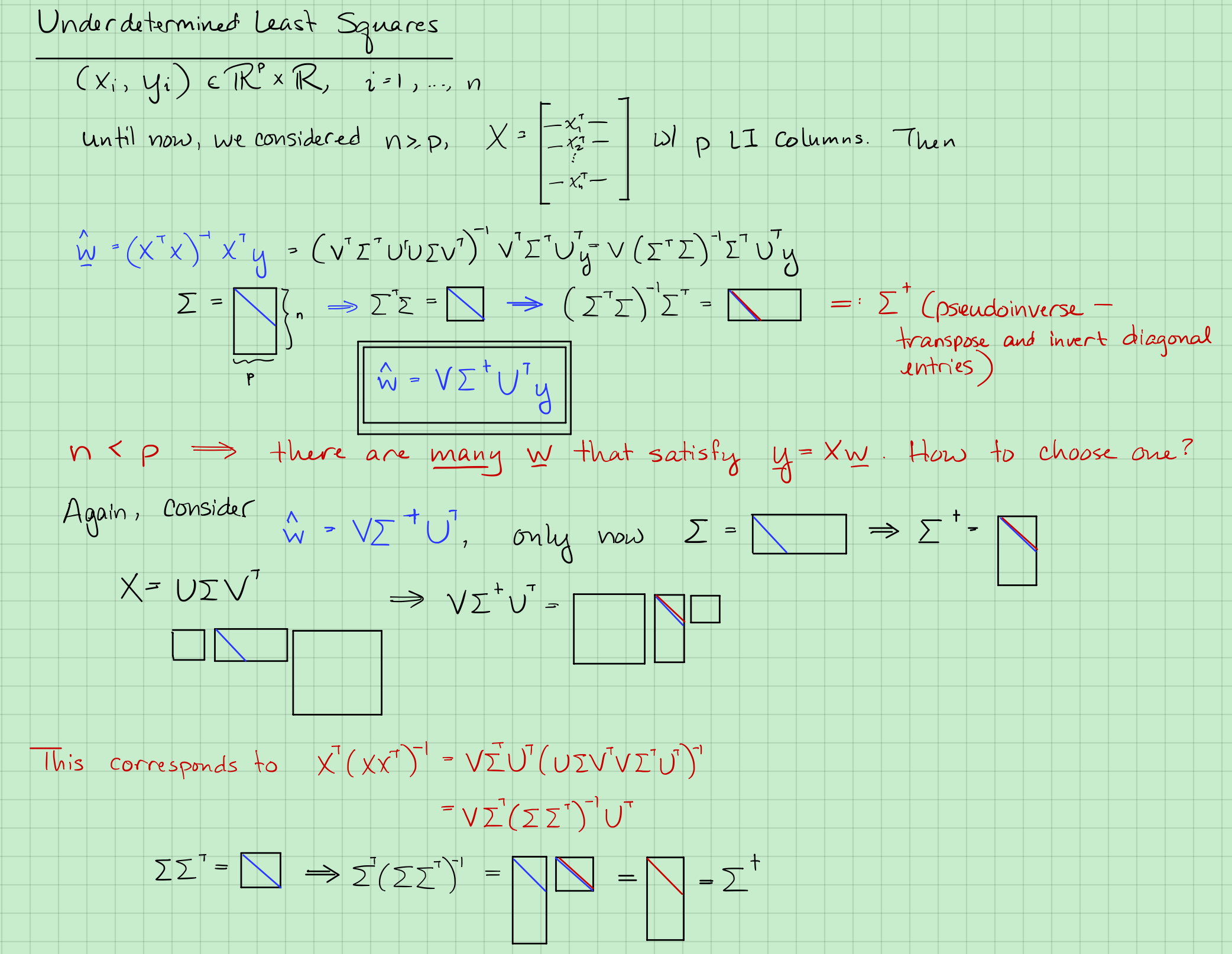

跟前面提到的一样有:
假设$n \ge p$ & $X$有$p$个线性无关的列,那么
情形1:
如果$X= U \Sigma V^T$,其中$U : n\times n ,\ \ \Sigma: n \times p ,\ \ V^T: p \times p$, 那么
由下面两式,
可得:
继续化简式2,[利用式5,把 看作 ]
pseudo-inverse:
并且有上节课里提到的:
由式7得:
跟上节课一样:
情形2:
$p \ge n$, $X$ 有$n$个独立的行,
那么有无数解[ 无穷 个 满足 ].
Claim: $\hat w = V \Sigma^+ U^T$ has the smallest norm of any w $s.t: \ y = Xw$。我们从上面的$w$中挑出一个$\hat w$来使其有最小的范数,并且满足约束。
因为$X$是“瘦长型”矩阵,那么其伪逆为$\Sigma^+= \Sigma^T(\Sigma\Sigma^T)^{-1}$。
对于任意$w$要有$y = Xw$.我们想要得到
而,
回忆一下,
式11,变为:
我们现在只看中间项,它等价于, 利用 跟伪逆一样理由写成这样化简下 :
又因为 。只能是 .
所以式12等于:
3. Why is minimum norm good?
一些问题
Why can’t we set $\hat w = X^{-1}y$?
- $X^{-1}$does not exist。
When $\hat w = (X^TX)^{-1}X^Ty$ vs $\hat w = X^T(XX^T)^{-1}y$?
- $\hat w = (X^TX)^{-1}X^Ty$ : $n \ge p, \ X \ has \ p \ LI \ cols. $
- $\hat w = X^T(XX^T)^{-1}y$ : $p \ge n, \ X \ has \ n \ LI \ rows. $
In both cases,
is good.
4. Matrix Completion

$X \in \mathbb{R}^{n \times p}$,assume $rank(X) = r \leq min(n, p)$, we observe $X_ij \ for (i, j)\in \Omega$
5. Singular Value Thresholding
 wechat
wechat alipay
alipay





