VGG 网络
1. VGG结构:
VGG 原文在:VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION
在ABSTRACT 中:
Our main contribution is a thorough evaluation of networks of increasing depth using an architecture with very small ( 3 × 3) convolution filters, which shows that a significant improvement on the prior-art configurations can be achieved by pushing the depth to 16–19 weight layers.
就说VGG最大特点是用小卷积滤波器(3x3),16-19层, Small filters, Deeper networks
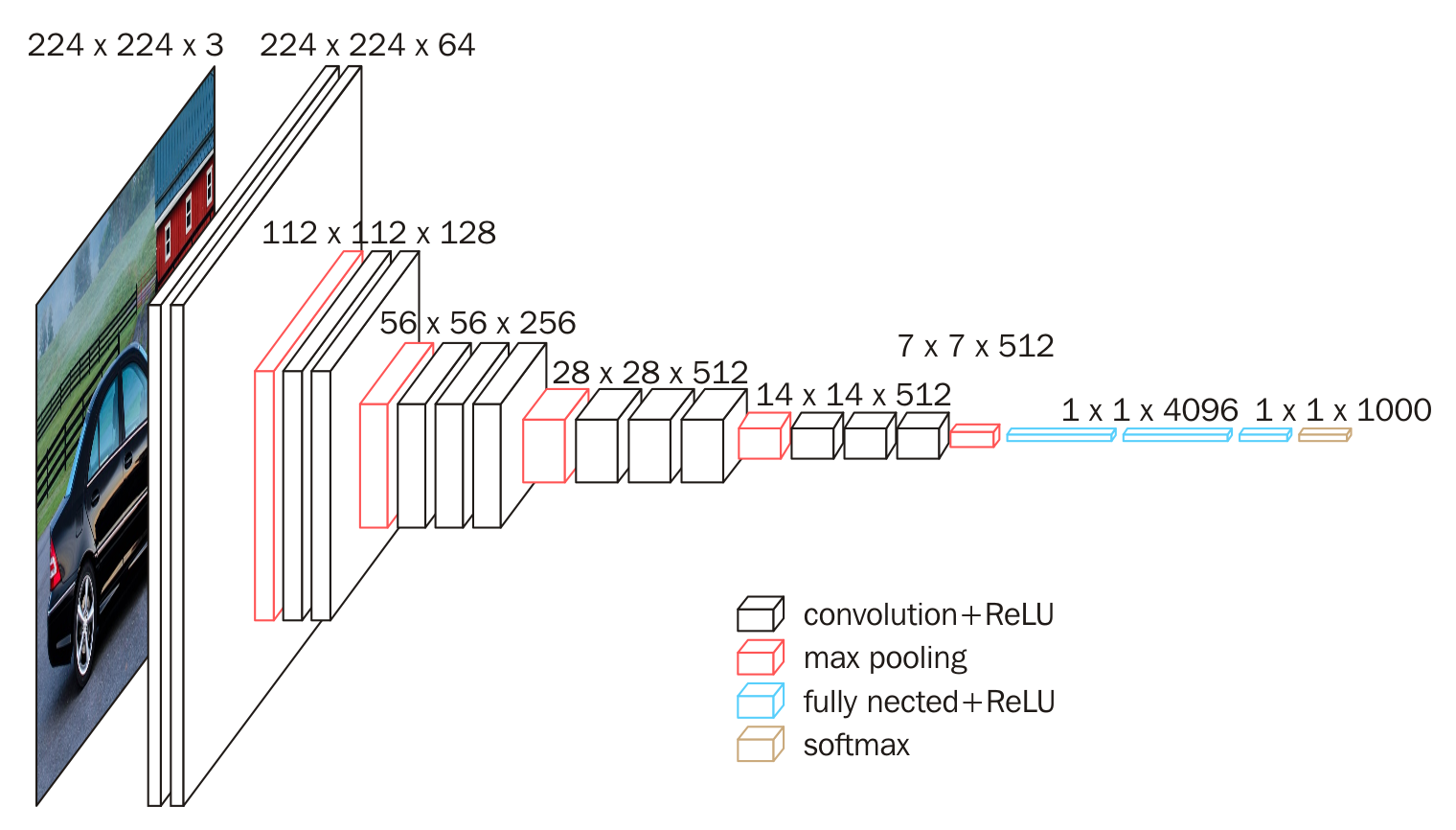
VGG16 结构示意图(对应论文Config D):
论文中VGG不同结构如下(C和D区别在有没有1x1卷积):

conv 3x3 优势
在VGG中,采用3个3x3的小卷积能够代替一个7x7的大卷积,要快速计算感受野,用这个 Fomoro AI
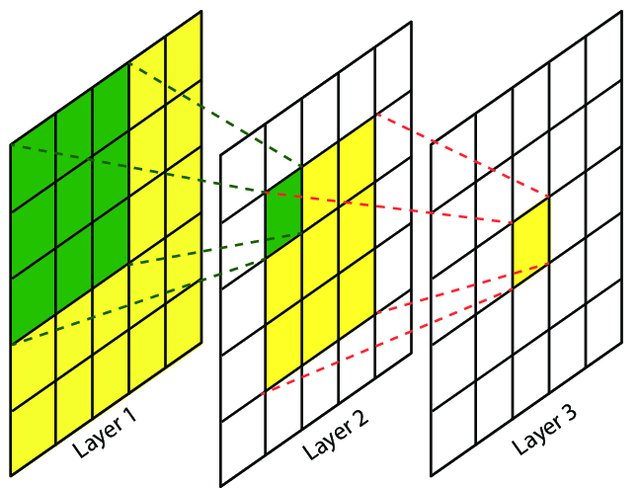
先计算特征图。带dilation的卷积操作,特征图size为:
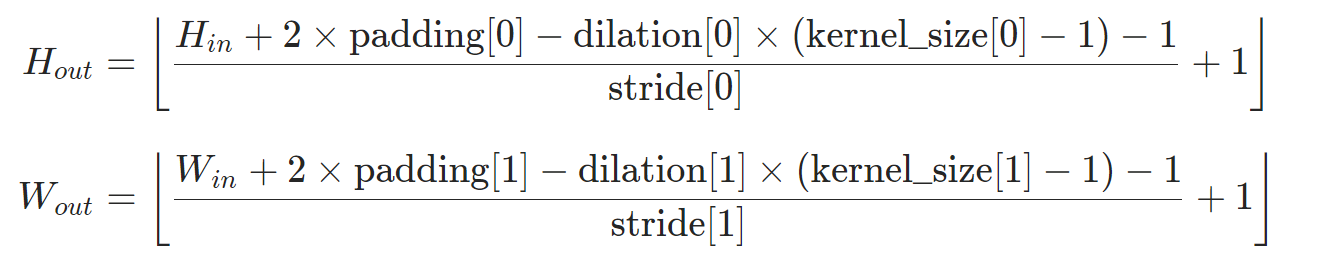
像cs231n中,(不带dilation)计算特征图公式:
其中, $W$是输入尺寸, $K$是kernel_size, $P$是padding大小, $S$是步长
那么,经过第一层卷积后, (K=3, S=1, padding=1), 输入224x224,输出为224x224,对应vgg 图中第一层卷积。
感受野计算code,详细见 A guide to receptive field arithmetic for Convolutional Neural Networks
其中,
| No. | Layers | Kernel Size | Stride |
|---|---|---|---|
| 1 | Conv1 | 3*3 | 1 |
| 2 | Pool1 | 2*2 | 2 |
| 3 | Conv2 | 3*3 | 1 |
对于初始感受野$l_0=1$,各层感受野分别为:
那么像图3层layer感受野中,Layer1中感受野为1,Layer2中感受野为(按VGG16 中卷积层 $f_k=3, s_i=1$ ):3, Layer3为5, Layer4为7.也是7x7的感受野。
更重要的是参数量大大降低,
一个7x7卷积核的参数量为49, 3个3x3的卷积核计算量为3x3x3.
如何理解卷积层的参数量和计算量?
- 参数量:参于计算参数的个数,占用内存空间(考虑bias)
- FLOPS: 每秒浮点运算次数,理解为计算速度。是衡量硬件性能的指标
- FLOPs: 浮点运算数,理解为计算量。可以用来衡量算法、模型的复杂度, H、W是输出feature map的尺寸(宽和高)
- MAC:乘加次数,用来衡量计算量
计算实例, 如下图,来自于 cs231n lecture9

原文对3x3的解释:
First, we incorporate three non-linear rectification layers instead of a single one, which makes the decision function more discriminative. Second, we decrease the number of parameters: assuming that both the input and the output of a three-layer $3 × 3$convolution stack has C channels, the stack is parametrised by $3 (3^2C^2) = 27C^2$ weights; at the same time, a single $7 × 7$ conv. layer would require $7^2C^2 = 49C^2 $parameters, i.e. 81%more. This can be seen as imposing a regularisation on the $7 × 7 $conv. filters, forcing them to have a decomposition through the $3 × 3$ filters (with non-linearity injected in between)
文章认为 LRN(local Response Normalization) 并没有提升模型在 ILSVRC 数据集上的表现,反而增加了内存消耗和计算时间。
模型 C 和 D 的层数一样,但 C 层使用了 1×1 的卷积核,用于对输入的线性转换,增加非线性决策函数,而不影响卷积层的接受视野。后面的评估阶段也有证明,使用增加的 1×1 卷积核不如添加 3×3 的卷积核。
Inference
[1] VGG16学习笔记
[2] VGG 论文阅读记录
[3] [卷积神经网络之VGG
[4] VGG论文翻译——中文版
[5] 感受野计算公式
[6] 感受野
[7] VGG 计算
 wechat
wechat alipay
alipay

