Chapter 06 Probability and Distributions
Chapter 06: Probability and Distributions
中英名词对照:
PMF:Probability Mass Function(概率质量函数)
PDF: Probability Density Function(概率密度函数)
CDF:Cumulative Distribution Function (累积分布函数)
i.i.d:Independent and identically distributed
median: 中位数
mode: 众数
1. Sum Rule, Product Rule, and Bayes’ Theorem
sum rule:
product rule
- Bayes’ theorem:
后验概率正比于似然 $\times$ 先验概率
likelihood 也可称作measurement model
假设我们有一些关于隐变量$\boldsymbol{x}$先验$p(\boldsymbol{x})$,以及关于$\boldsymbol{x}$和第二个变量$\boldsymbol{y}$之间的关系$p \left( \boldsymbol{y} \left|\boldsymbol{x}\right. \right)$。如果我们观察$\boldsymbol{y}$,我们可以使用Bayes’理论来得到公式3.
$p(\boldsymbol{x})$,封装了我们在观察任何数据之前对隐变量$\boldsymbol{x}$主观先验知识。我们可以选择任何对我有意义的先验知识,但至关重要的是确保先验在所有可能的$\boldsymbol{x}$有非零的pdf,即使其非常罕见。
似然${p(\boldsymbol{y} \mid \boldsymbol{x})}$描述$\boldsymbol{x}$和$\boldsymbol{y}$直接的关系,并且在离散概率分布情况下,如果我们知道隐变量$\boldsymbol{x}$,它是数据$\boldsymbol{y}$的概率。注意,似然不是$\boldsymbol{x}$的分布,而是$\boldsymbol{y}$。我们称${p(\boldsymbol{y} \mid \boldsymbol{x})}$为给定$\boldsymbol{y}$的$\boldsymbol{x}$的似然,或给定$\boldsymbol{x}$的$\boldsymbol{y}$的概率, 但绝对不能称$\boldsymbol{y}$的似然。
后验${p(\boldsymbol{x} \mid \boldsymbol{y})}$得益于大量Bayes统计学,因为它准确表达了我们在观察$\boldsymbol{y}$后了解$\boldsymbol{x}$的兴趣。
根据贝叶斯定理公式3,一个随机变量在给定另一随机变量值之后的后验概率分布可以通过先验概率分布与似然函数相乘并除以归一化常数求得
:上式为给出了随机变量$X$在给定数据$Y=y$后的后验概率分布函数,式中
- 为 的先验密度函数,
- 为 的似然函数,
- 为归一化常数,
- 为考虑了数据 后 的后验密度函数。
1. Likelihood function
In statistics, the likelihood function often simply called the likelihood measures the goodness of fit of a statistical model to a sample of data for given values of the unknown parameters. It is formed from the joint probability distribution of the sample, but viewed and used as a function of the parameters only, thus treating the random variables as fixed at the observed values.
在数理统计学中,似然函数是一种关于统计模型中的参数的函数,表示模型参数中的似然性。似然函数在统计推断中有重大作用,如在最大似然估计和费雪信息之中的应用等等。“似然性”与“或然性”或“概率”意思相近,都是指某种事件发生的可能性,但是在统计学中,“似然性”和“概率”(或然性)又有明确的区分:概率,用于在已知一些参数的情況下,预测接下来在观测上所得到的结果;似然性,则是用于在已知某些观测所得到的结果时,对有关事物之性质的参数进行估值。
在这种意义上,似然函数可以理解为条件概率的逆反。在已知某个参数$B$时,事件$A$会发生的概率写作:
利用贝叶斯定理,
因此,我们可以反过来构造表示似然性的方法:已知有事件$A$发生,运用似然函数$\mathbb{L}(B \mid A)$,我们估计参数$B$的可能性。形式上,似然函数也是一种条件概率函数,但我们关注的变量改变了:
注意到这里并不要求似然函数满足归一性:$\sum_{b \in \mathcal{B}}P(A \mid B=b) = 1$。一个似然函数乘以一个正的常数之后仍然是似然函数。对所有$\alpha > 0$,都可以有似然函数:
2. 边缘似然/证据
- the marginal likehood/evidence:
定义上,边缘似然是对应隐变量$x$数值积分。
在统计学中, 边缘似然函数(marginal likelihood function),或积分似然(integrated likelihood),是一个某些参数变量边缘化的似然函数(likelihood function) 。在贝叶斯统计范畴,它也可以被称作为 证据 或者 模型证据 的。
2. 均值和协方差
- Means and Covariances
均值和(协)方差经常用来描述概率分布的性质(期望值和范围)。
期望值的概念是机器学习的核心,并且概率本身的基础概念也源自于它。
——(Whittle, 2000).
1. 期望值
- Expected Value
期望值函数$g: \mathbb{R} \rightarrow \mathbb{R}$单一连续随机变量$X \sim p(x)$给定如下:
对应离散随机变量$X \sim p(x)$:
$\mathcal{X}$:随机变量$X$可能结果的集合 target space
注意:
我们把多维随机变量$X$看作有限的单一随机变量的向量$[X_1, \cdots, X_D]^{T}$。对于多维随机变量,定义基于元素的期望值:
其中: 表示对应向量 的第 个元素的期望值。
2. 均值
对于状态量 随机变量 的均值是一个平均值,其定义如下:
其中,$d = 1, \cdots, D$;$d$表示对应$x$的维数。遍历随机变量$x$目标空间的状态量$\mathcal{X}$积分或求和。
3. 协方差(Covariance)定义及推导
两个多维随机变量$X, Y \in \mathbb{R}$之间的协方差,给定为它们与均值的偏差的积的期望:
因为期望计算是线性的,对于一个实值函数$f(\boldsymbol{x}) = ag(\boldsymbol{x}) + bh(\boldsymbol{x})$, 当$a, b \in \mathbb{R} 且 \boldsymbol{x} \in \mathbb{R}^{D}$我们可以得到:
所以,公式10可以有如下推导:
即:
4. 多元随机变量的方差
- Covariance (Multivariate)
两元随机变量$X$和$Y$及其对应状态$\boldsymbol{x} \in \mathbb{R}^{D} 和 \boldsymbol{y} \in \mathbb{R}^{D}$,$X和 Y$之间的协方差为:
5. 方差
- Variance
带有状态$\boldsymbol{x} \in \mathbb{R}^{D}$和均值向量$\boldsymbol{\mu} \in \mathbb{R}^{D}$的随机变量$X$方差定义为:
$D \times D$的矩阵被称作多元随机变量的协方差矩阵 covariance matrix 。协方差矩阵是对称和半正定的,并且告诉我们数据范围的信息。在对角线上,协方差矩阵含有边缘方差:
$\backslash_{i} $表示”除了$i$之外的所有变量”。非对角线元素是互协方差项$\operatorname {Cov}[x_i, y_i]$,$i, j = 1, \cdots, D, i \ne j$。
6. 相关
- Correlation
两个随机变量$X,Y$之间的相关性定义为:
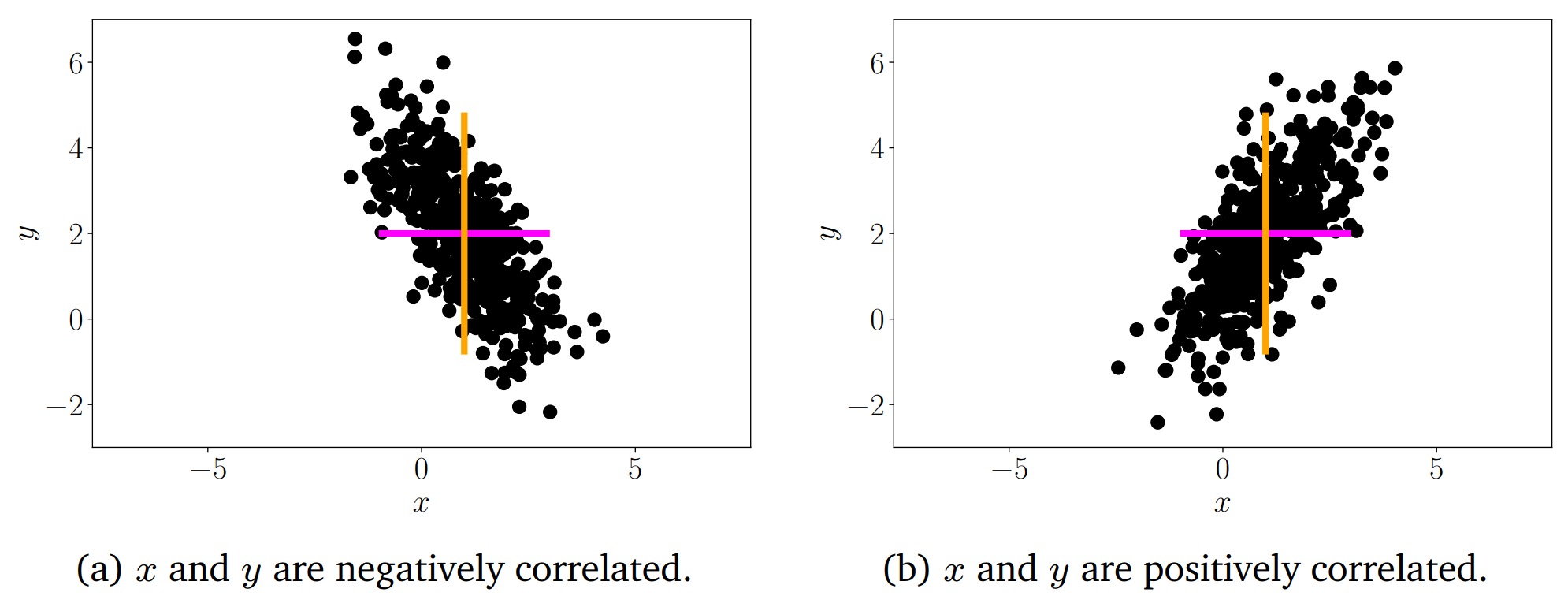
上图中表明,正相关$corr[x, y]$意味着当$x$变大,$y$也随之变大。负相关$corr[x, y]$意味着当$x$变大,$y$也随之变小。
3. 经验均值和协方差
- Empirical Means and Covariances
在机器学习中,我们需要从数据中学习经验的观察结果。
我们用有限的数据集 size N 来构建经验统计,它是一个同一随机变量有限数值的函数。
我们观察数据,就是我们看每一个随机变量$x_1, x_2, \cdots, x_N$之间的联系和应用经验统计。
具体来说,对于均值,给定一个特殊的数据集我们获得均值的估计,这称作经验均值或者样本均值sample mean .经验协方差也一样适用。
1. 经验均值和协方差
经验均值向量是每一个观察变量的算术平均,其定义如下:
跟经验均值一样,经验协方差矩阵$D \times D$定义为:
为了计算特定数据集的统计信息,我们用观察量 ,biased estimate 代入公式17.18来计算。经验协方差矩阵是对称半正定的。
2. 方差的3种表达式
1. 标准方差定义
对应协方差定义,它是随机变量$X$与其期望值$\mu$偏差平方的期望:
2. 方差的原始分数公式
记作:“平方的均值减去均值的平方”。
3. The sum of $N^{2}$ pairwise differences is the empirical variance of the observations
当它用到随机变量的仿射变换时,均值和(协)方差表现一些有用的特性。考虑均值为$\boldsymbol{\mu}$、协方差矩阵$\boldsymbol{\Sigma}$随机变量$X$和关于一个$\boldsymbol{x}$(决定论的)仿射变换$\boldsymbol{y} = \boldsymbol{A}\boldsymbol{x} + \boldsymbol{b}$。随机变量$\boldsymbol{y}$,其均值向量和协方差矩阵定义为:
而且:
这里,$\boldsymbol{\Sigma} = \mathbb{E}[\boldsymbol{x}\boldsymbol{x}\top] - \boldsymbol{\mu}\boldsymbol{\mu}\top$是$\boldsymbol{X}$的协方差。
3. Statistical Independence(独立)
1. 独立
两个随机变量$X, Y$在统计上独立当且仅当:
直觉地,如果$\boldsymbol{y}$的值不增加$\boldsymbol{x}$任何信息,两个随机变量$X, Y$独立。
如果$X, Y$统计上独立,有:
2.条件独立 Conditional Independence
给定$Z$,两个随机变量$X, Y$条件独立,当且仅当:
$\mathcal{Z}$是随机变量$Z$的状态量集合.$X \perp Y \mid Z$表示给定$Z$情况下$X$条件独立$Y$,或者“我们已知$z$,关于$y$的信息不改变$x$的信息”。
公式25可以理解为“给定关于$z$的信息, $x \ and \ y$ 的分布的分解”。运用概率的积的法则,公式25左边展开可以得到:
比较公式25、26右边部分,我们得到:
4. 随机变量的内积
1. 两个随机变量的内积定义
如果我们有两个不相关随机变量$X,Y$, uncorrelated random variable, covariance value is zero 有:
如果随机变量$X,Y$是不相关的,它们在对应向量空间是正交向量,应用毕达哥拉斯定理可以有如下示意图
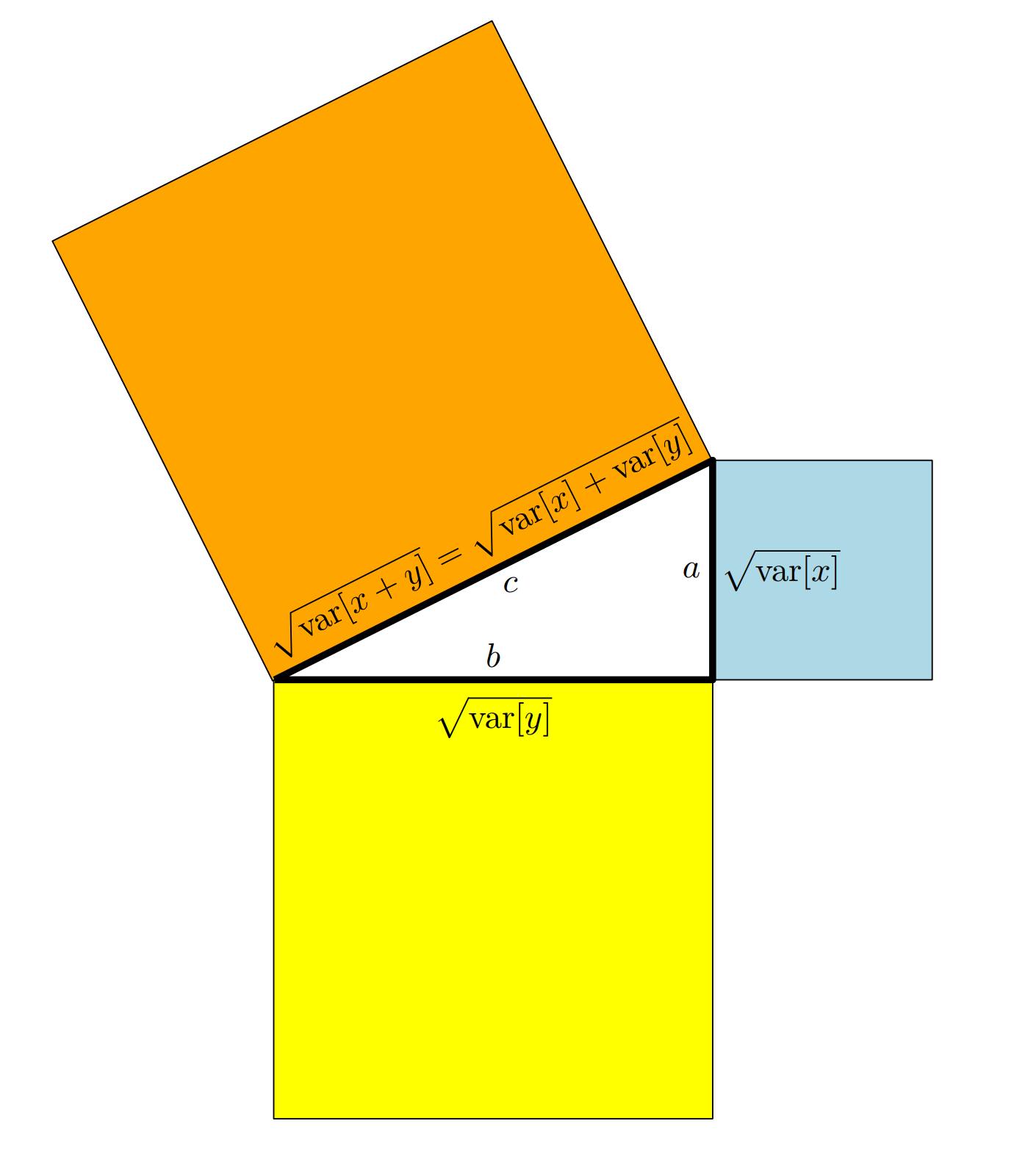
随机变量在向量空间可以被看着向量,并且我们定义内积来获得随机变量的几何性质。
对0均值随机变量$X,Y$,我们得到内积。我们看到协方差矩阵是对称正定的,对每个参数都是线性的。随机变量的长度为:
其标准偏差。随机变量的”长”,是不确定的,但一个长为0的随机变量是确定的。其还有如下性质:
如果我们观察两个随机变量$X,Y$之间的角度$\theta$,我们得到:
随机变量$X,Y$是正交的当且仅当$\operatorname{Cov}[x, y] = 0$,意味着它们是无关的。
4. 高斯分布
1. 什么是高斯分布?
二元随机变量$x_1, x_2$的高斯分布如下:
100个样本的高斯分布:
a)一维实例
b)二维实例
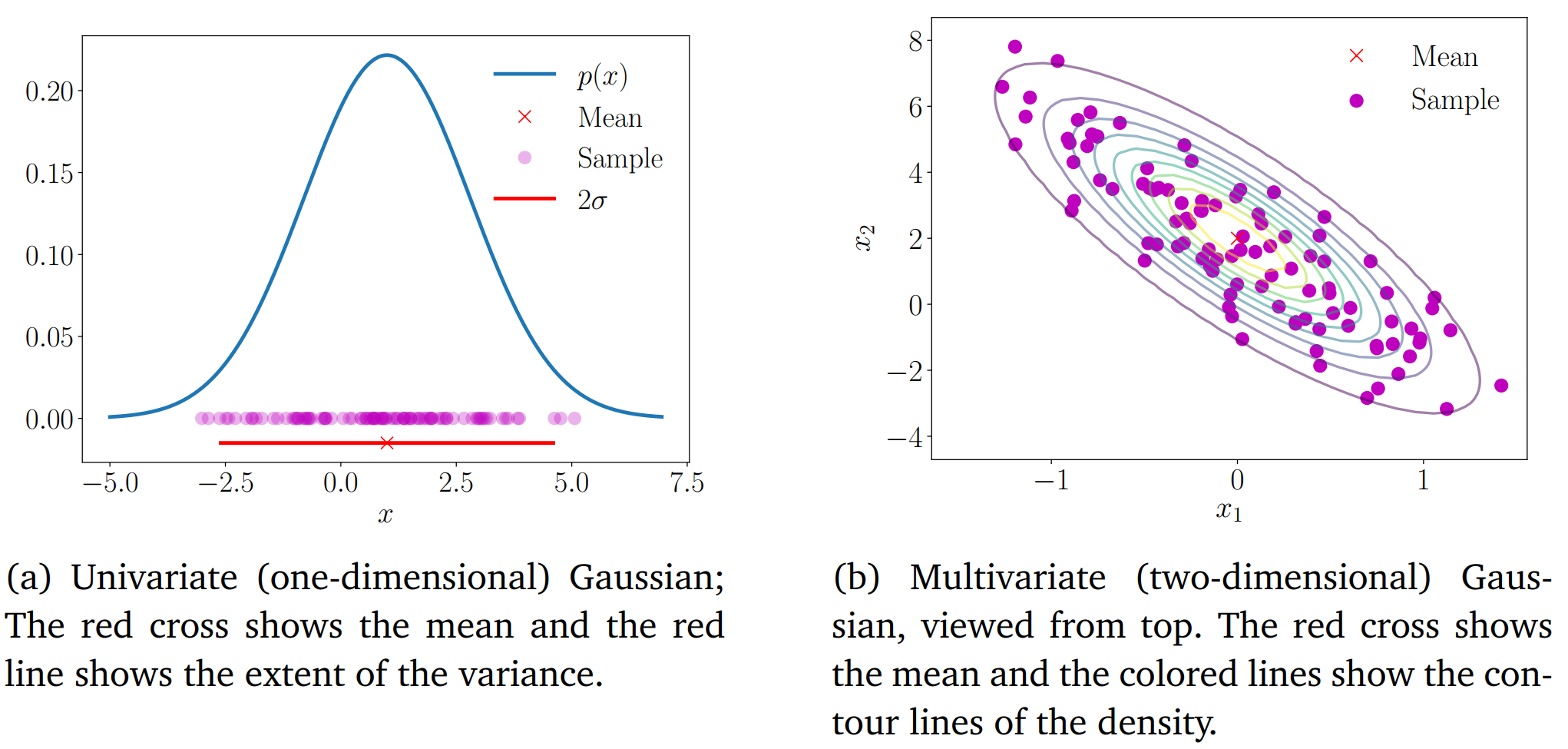
100个样本的高斯分布示意图 引用自https://mml-book.com
对于单一随机变量,高斯分布的概率密度函数定义为:
以均值向量$\boldsymbol{\mu}$和协方差矩阵$\boldsymbol{\Sigma}$完全地特征化的多元随机变量的高斯分布可以定义为:
其中, 。
当 且 时,称作标准正态分布。
2. 多重高斯分布 Gaussians 的边界 Marginal 和条件 Conditional
我们清晰地按照级联状态 写出高斯分布:
其中, 是 边缘协方差矩阵。同时, 是 和 之间的互协方差矩阵。
条件分布conditional distribution 也是高斯分布,其定义为:
注意,公式35计算均值时, 是一个观察量而不是变量。
一个联合高斯分布的边缘分布,其高斯分布应用sum rule计算给定为:
对应的结果也适用于$p(\boldsymbol{y})$,这通过边缘化$\boldsymbol{x}$来获得。
3. 高斯分布密度的积
两个高斯分布的积,是按成比例的高斯分布,给定为:
比例常数$c$,它可以按照高斯密度函数的形式,以$\boldsymbol{a}$或$\boldsymbol{b}$和一个”夸张的”协方差矩阵$\boldsymbol{A+B}$写作,如,$\mathcal{N}(\boldsymbol{a} \mid \boldsymbol{b}, \boldsymbol{A + B}) \text{ 或 } \mathcal{N}(\boldsymbol{b} \mid \boldsymbol{a}, \boldsymbol{A + B})$.
注意:为了记号简便,我们有时用$\mathcal{N}(\boldsymbol{x} \mid \boldsymbol{m}, \boldsymbol{S})$来描述高斯密度函数的形式,即使$\boldsymbol{x}$不是一个随机变量。当我们写作如下公式时,仅需要做前面的证明。
高斯分布的和、线性变换 Sums and Linear Transformations
如果是独立的高斯随机变量,那么也是高斯分布,给定为:
两个单一变量混合高斯分布密度
这里标量$0< \alpha < 1$是混合权重, 是有不同参数的单一高斯分布密度,如, 。
混合高斯分布密度 $p(x)$ 用每个随机变量的均值的权重之和来定义:
混合高斯分布密度$p(x)$的方差给定为:
证明:$\mathbb{E}[x]$
而要证明$\mathbb{V}(x)$,得证明$\mathbb{E}(x^{2})$.
公式46最后两步是因为:$\sigma^{2} = \mathbb{E}[x^2] - \mu^{2}$。重新整理就是随机变量平方的均值等于均值和方差平方和。因此,方差可以定义为:
注意:前面的偏差可以应用到任何密度函数,但自从高斯分布完全由均值和方差决定后,混合密度函数也可以确定了。
总方差定理 Law of total variance
通常指对于两个随机变量$X \, 和 \, Y$,有:
即条件方差的期望加上条件均值的方差。
我们认为二元高斯随机变量$X$,对其应用线性变换$\boldsymbol{Ax}$。结果是一个有均值zero协方差为$\boldsymbol{A}\boldsymbol{A}^{\top}$高斯分布。观察到,加上一个常数向量将会改变分布的均值,不影响其方差,那么,随机变量$\boldsymbol{x + \mu}$有均值$\boldsymbol{\mu}$和单位协方差矩阵。因此,高斯分布进行任何线性、仿射变换后都是高斯分布。
考虑高斯分布随机变量$X \sim \mathcal{N}(\boldsymbol{\mu}, \boldsymbol{\Sigma})$,对于给定恰当形状的矩阵$\boldsymbol{A}$,让$Y$成为$\boldsymbol{x}$进行$\boldsymbol{y = Ax}$变换后的的随机变量。我们利用如下线性操作来计算$\boldsymbol{y}$
的均值:
方差:
随机变量$\boldsymbol{y}$分布服从于:
现在,我们再考虑相反的变换:当一个随机变量有均值, 且是另一个随机变量的线性变换。对于给定一个满秩矩阵$\boldsymbol{A} \in \mathbb{R}^{M \times N}$,当 $M \ge N$, $\boldsymbol{y} \in \mathbb{R}^{M}$是一个均值为$\boldsymbol{Ax}$的高斯随机变量, 即:
其对应概率分布$p(\boldsymbol{x})$是什么?如果 $p(\boldsymbol{A})$是可逆的,我们可以写作$\boldsymbol{x} = \boldsymbol{A}^{-1}\boldsymbol{y}$,应用前面提到的变换。然而,通常$\boldsymbol{A}$是不可逆,我们使用相似的方法即伪逆。我们两边同乘$\boldsymbol{A}^{\top}$,然后逆变换$\boldsymbol{A}^{\top}\boldsymbol{A}$,它是对称正定的,给我们如下联系:
因此,$\boldsymbol{y}$的逆变换是$\boldsymbol{x}$,我们可以得到:
5. Conjugacy and the Exponential Family
 wechat
wechat alipay
alipay





